How to Find the Best Pre-Trained Models for Image Classification

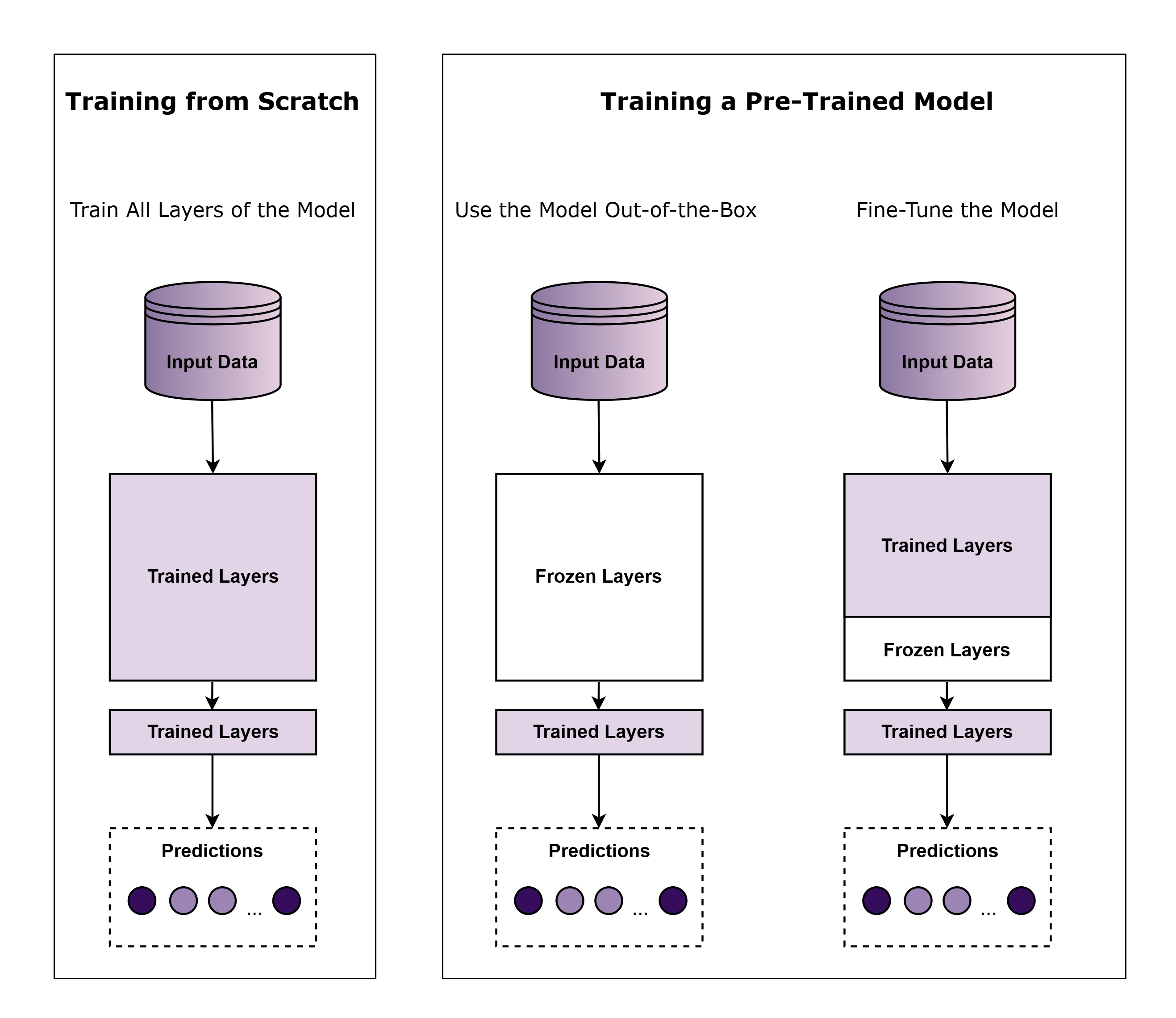
A pre-trained model is a neural network that has already been trained on a large dataset to perform specific tasks, such as image classification or object detection. These models are highly valuable, allowing us to build on previous knowledge rather than starting from scratch.
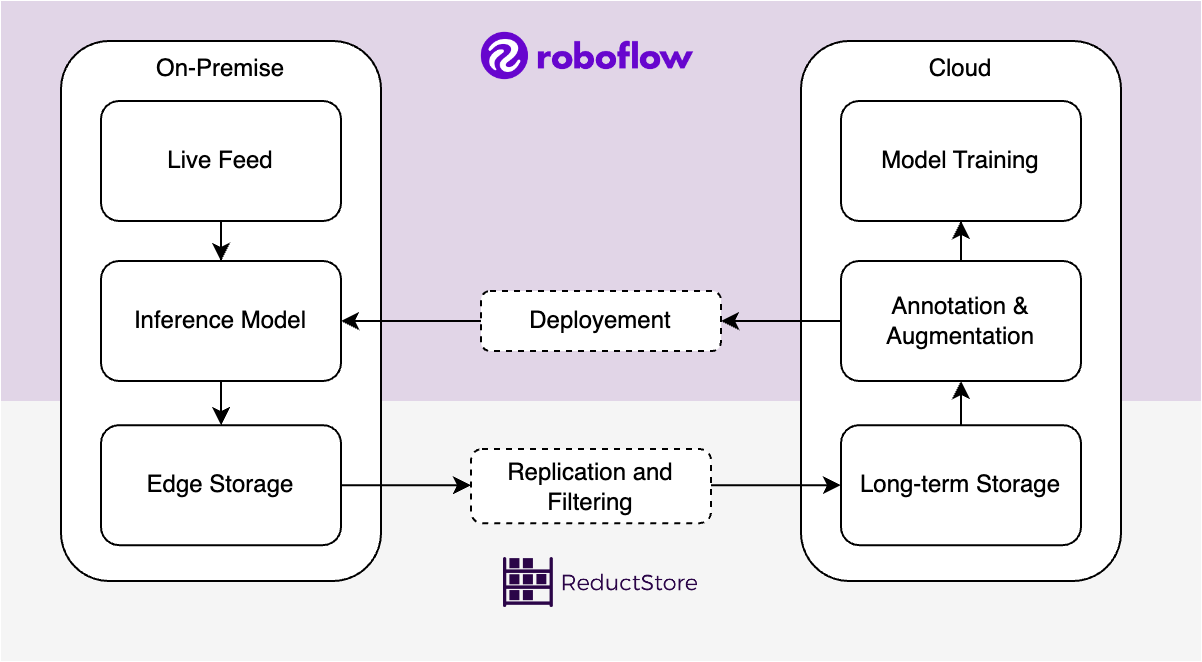
However, computer vision models often require large datasets of labeled images or videos, which can quickly become challenging to manage, especially when sourced from continuous data streams. ReductStore addresses this need by providing an efficient and reliable time-series object store capable of handling large volumes of high-frequency, unstructured data such as video streams or labeled images. For practical guidance on implementing ReductStore and integrating it with Roboflow to develop high-performing computer vision models, refer to the guide: Computer Vision Made Simple with ReductStore and Roboflow.