How to Store Images in ROS2

ROS2 is widely used for building robotic systems with sensors like cameras, LiDAR, and IMUs. While it's great for communication (e.g., publishing and subscribing to topics), it lacks a built-in solution for storing large amounts of unstructured data, such as images.
Bag files are commonly used to store data in ROS2, but they aren't a good fit for long-term storage or real-time streaming. They're mainly meant for recording and replaying mission data or episodes, not for managing large volumes of unstructured data.
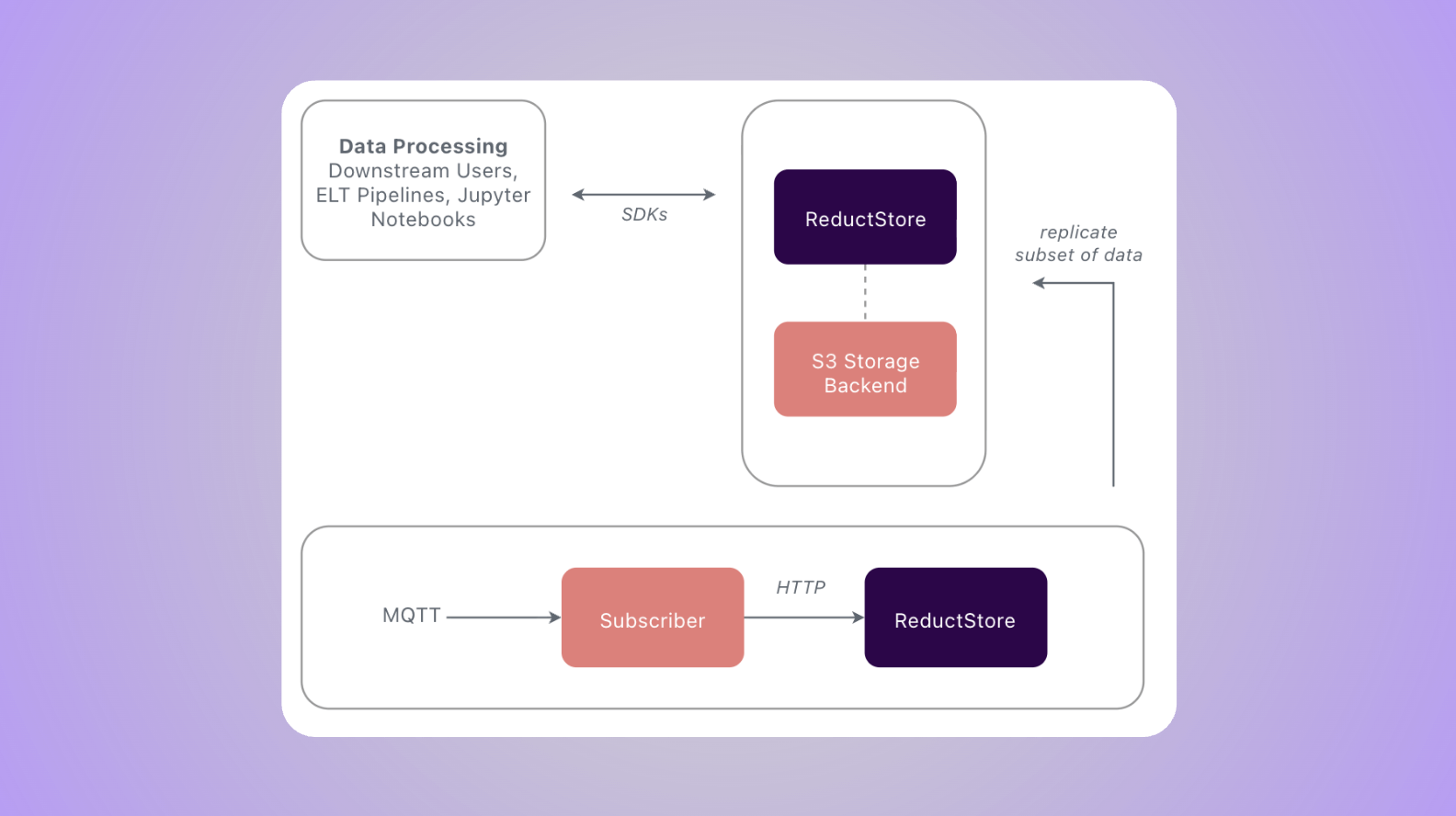
Addressing this challenge, this blog post will guide you through setting up ROS2 with ReductStore a high-performance storage and streaming solution optimized for unstructured, time-series data.
We will focus specifically on image data, but if you are interested in a more general overview you can read How to Store and Manage Robotic Data which covers the challenges and strategies for storing and managing robotic data in general.
For the full code example, we will be using the reduct-ros-example repository, which provides a complete implementation of the concepts discussed in this article.