CRA-Compliant Robotics Data Storage 2026: How to Solve the Data Storage Challenges of the CRA

The CRA Deadline Every German Robot Operator Must Face
The EU Cyber Resilience Act (Regulation (EU) 2024/2847) is the “GDPR for connected products.” It entered into force on 10 December 2024, with critical milestones approaching fast:
- 11 September 2026: Mandatory reporting of actively exploited vulnerabilities and severe incidents (24-hour early warning, 72-hour full notification).
- 11 December 2027: Full compliance — Security by Design, lifecycle support (minimum 5 years), technical documentation, and CE marking.
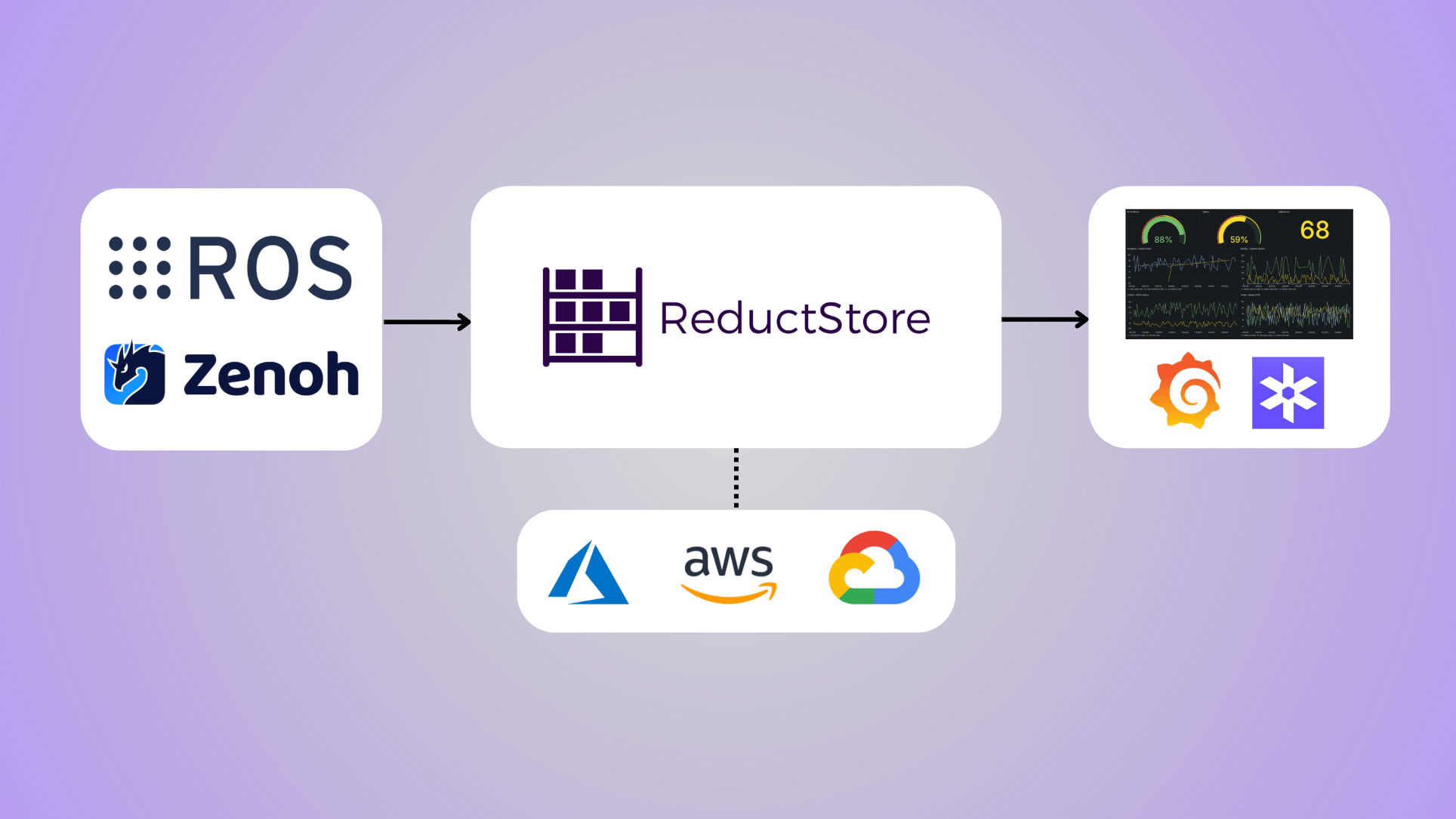
For robotics fleets (AMRs, cobots, autonomous systems, and ROS 2-based platforms) the stakes are particularly high. These systems are “products with digital elements” (often Class II or critical), generating massive multimodal data streams (camera feeds, LiDAR, IMU, logs, ROS bags) under real production constraints: intermittent connectivity, edge hardware limits, and high physical safety risks.
Generic storage solutions force painful trade-offs: either accept data loss and compliance gaps, or accept exploding costs and slow performance. ReductStore eliminates this trade-off.