Data Querying From ReductStore Database
ReductStore is a time series database that provides efficient data retrieval capabilities. This guide explains how to query data from ReductStore using the CLI, HTTP API, and SDKs.
Concepts
ReductStore provides an efficient data retrieval solution by batching multiple records within a specified time interval into a single HTTP request, which is beneficial for managing large volumes of data as it reduces the number of requests and overall delay.
The query process is designed as an iterator, returning a batch of records in each iteration. This method allows data to be processed in segments, an approach that is useful when managing large datasets.
While it is possible to retrieve a record by its timestamp, this method is less optimal than querying by a time range due to the lack of batching. However, this approach can be useful for querying specific versions of non-time series records, such as AI models, configurations, or file versions, when timestamps are used as identifiers.
Query Parameters
Data can be queried using the ReductStore CLI, SDKs or HTTP API. The query parameters are the same for all interfaces and are divided into two categories: filter and control parameters.
Filter Parameters
Filter parameters are used to select records based on specific criteria. You can combine multiple filter parameters to create complex queries. This is the list of filter parameters, sorted by priority:
| Parameter | Description | Type | Default |
|---|---|---|---|
start | Start time of the query | Timestamp | The timestamp of the first record in the entry |
end | End time of the query | Timestamp | The timestamp of the last record in the entry |
when | Conditional query | JSON-like object | No condition |
each_s | Return a record every S seconds | Float | Disabled |
each_n | Return only every N record | Integer | Disabled |
limit | Limit on the number of records | Integer | All records are returned |
Time Range
The time range is defined by the start and end parameters. Records with a timestamp equal to or greater than start and less than end are included in the result. If the start parameter is not set, the query starts from the begging of the entry. If the end parameter is not set, the query continues to the end of the entry. If both start and end are not set, the query returns the entire entry.
When Condition
The when parameter is used to filter records based on labels. The condition is specified as a JSON-like object. The query returns only records that match the specified condition. The condition can be a simple equality check or a more complex expression using comparison operators. For more information on conditional queries, see the Conditional Query Reference.
One Record Every S Seconds
The each_s parameter returns a record every S seconds. This parameter is useful when you need to resample data at a specific interval. You can use floating-point numbers for better precision. The default value is 0, which means all records are returned.
Every Nth Record
The each_n parameter returns only every Nth record. This parameter is useful when you need to downsample data by skipping records. The default value is 1, which means all records are returned.
Limit Records
The limit parameter restricts the number of records returned by a query. If the dataset has fewer records than the specified limit, all records are returned.
Control Parameters
There are also more advanced parameters available in the SDKs and HTTP API to control the query behavior:
| Parameter | Description | Type | Default |
|---|---|---|---|
ttl | Time-to-live of the query. The query is automatically closed after TTL | Integer | 60 |
head | Retrieve only metadata | Boolean | False |
continuous | Keep the query open for continuous data retrieval | Boolean | False |
poll_interval | Time interval in seconds for polling data in continuous mode data in continuous mode | Integer | 1 |
strict | Enable strict mode for conditional queries | Boolean | False |
TTL (Time-to-Live)
The ttl parameter determines the time-to-live of a query. The query is automatically closed when the specified time has elapsed since it was created. This prevents memory leaks by limiting the number of open queries. The default TTL is 60 seconds.
Head Flag
The head flag is used to retrieve only metadata. When set to true, the query returns the records' metadata, excluding the actual data. This parameter is useful when you want to work with labels without downloading the content of the records.
Continuous Mode
The continuous flag is used to keep the query open for continuous data retrieval. This mode is useful when you need to monitor data in real-time. The SDKs provide poll_interval parameter to specify the time interval for polling data in continuous mode. The default interval is 1 second.
Strict Mode
The strict flag is used to enable strict mode for conditional queries in the where parameter. In strict mode, the query fails if the condition is invalid or contains an unknown field.
When the strict mode is disabled, the invalid condition is considered as false and the unknown field is ignored.
Typical Data Querying Cases
This section provides guidance on implementing typical data querying cases using the ReductStore CLI, SDKs, or HTTP API. All examples are designed for a local ReductStore instance, accessible at http://127.0.0.1:8383 using the API token 'my-token'.
For more information on setting up a local ReductStore instance, see the Getting Started guide.
Querying Data by Time Range
The most common use case is to query data within a specific time range:
- Python
- JavaScript
- Rust
- C++
- CLI
- Web Console
- cURL
import time
import asyncio
from reduct import Client, Bucket
async def main():
# Create a client instance, then get or create a bucket
async with Client("http://127.0.0.1:8383", api_token="my-token") as client:
bucket: Bucket = await client.create_bucket("my-bucket", exist_ok=True)
ts = time.time()
await bucket.write(
"py-example",
b"Some binary data",
ts,
)
# Query records in the "py-example" entry of the bucket
async for record in bucket.query("py-example", start=ts, stop=ts + 1):
# Print meta information
print(f"Timestamp: {record.timestamp}")
print(f"Content Length: {record.size}")
print(f"Content Type: {record.content_type}")
print(f"Labels: {record.labels}")
# Read the record content
content = await record.read_all()
assert content == b"Some binary data"
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
import { Client } from "reduct-js";
import assert from "node:assert";
// Create a client instance, then get or create a bucket
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
const bucket = await client.getOrCreateBucket("bucket");
// Send a record to the "js-example" entry with the current timestamp in microseconds
const timestamp = BigInt(Date.now()) * 1000n;
let record = await bucket.beginWrite("js-example", timestamp);
await record.write("Some binary data");
// Query records in the "js-example" entry of the bucket
for await (let record of bucket.query(
"js-example",
timestamp,
timestamp + 1000n,
)) {
// Print meta information
console.log(`Timestamp: ${record.time}`);
console.log(`Content Length: ${record.size}`);
console.log(`Content Type: ${record.contentType}`);
console.log(`Labels: ${JSON.stringify(record.labels)}`);
// Read the record content
let content = await record.read();
assert(content.toString() === "Some binary data");
}
use std::time::{Duration, SystemTime};
use bytes::Bytes;
use futures::StreamExt;
use reduct_rs::{ReductClient, ReductError};
use tokio;
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a client instance, then get or create a bucket
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
let bucket = client.create_bucket("test").exist_ok(true).send().await?;
// Send a record to the "rs-example" entry with the current timestamp
let timestamp = SystemTime::now();
bucket
.write_record("rs-example")
.timestamp(timestamp)
.data("Some binary data")
.send()
.await?;
// Query records in the time range
let query = bucket
.query("rs-example")
.start(timestamp)
.stop(timestamp + Duration::from_secs(1))
.send()
.await?;
tokio::pin!(query);
while let Some(record) = query.next().await {
let record = record?;
println!("Timestamp: {:?}", record.timestamp());
println!("Content Length: {}", record.content_length());
println!("Content Type: {}", record.content_type());
println!("Labels: {:?}", record.labels());
// Read the record data
let data = record.bytes().await?;
assert_eq!(data, Bytes::from("Some binary data"));
}
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
using std::chrono_literals::operator ""s;
int main() {
// Create a client instance, then get or create a bucket
auto client = IClient::Build("http://127.0.0.1:8383", {.api_token="my-token"});
auto [bucket, create_err] = client->GetOrCreateBucket("my-bucket");
assert(create_err == Error::kOk);
// Send a record with labels and content type
IBucket::Time ts = IBucket::Time::clock::now();
auto err = bucket->Write("cpp-example", ts,[](auto rec) {
rec->WriteAll("Some binary data");
});
assert(err == Error::kOk);
// Query records in a time range
err = bucket->Query("cpp-example", ts , ts+1s, {}, [](auto rec) {
// Print metadata
std::cout << "Timestamp: " << rec.timestamp.time_since_epoch().count() << std::endl;
std::cout << "Content Length: " << rec.size << std::endl;
std::cout << "Content Type: " << rec.content_type << std::endl;
std::cout << "Labels: " ;
for (auto& [key, value] : rec.labels) {
std::cout << key << ": " << value << ", ";
}
std::cout << std::endl;
// Read the content
auto [content, read_err] = rec.ReadAll();
assert(read_err == Error::kOk);
std::cout << "Content: " << content << std::endl;
assert(content == "Some binary data");
return true; // if false, the query will stop
});
assert(err == Error::kOk);
return 0;
}
reduct-cli alias add local -L http://localhost:8383 -t "my-token"
# Query data for a specific time range and export it to a local directory
reduct-cli cp local/example-bucket ./export --start "2021-01-01T00:00:00Z" --stop "2021-01-02T00:00:00Z"
- Open the Web Console at
http://127.0.0.1:8383in your browser. - Enter the API token if the authorization is enabled.
- Select the bucket that contains the data you want to query:
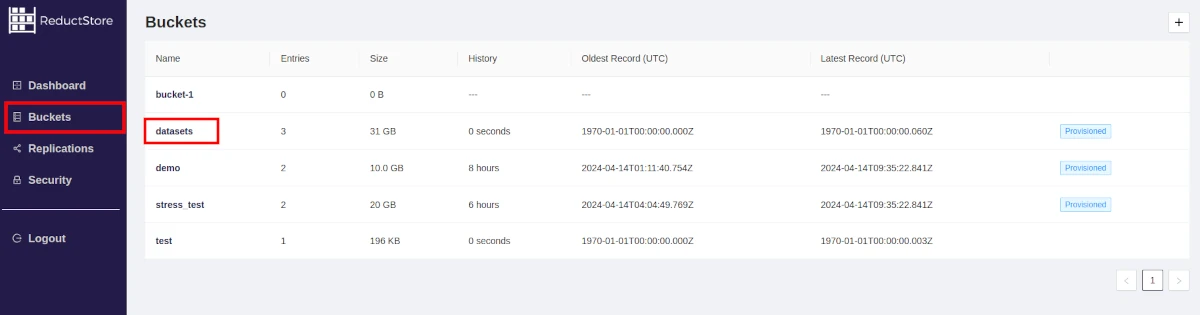
- You will see a list of all the entries in the bucket
- Click on the entry you want to query
- On the entry page you will see the query panel:
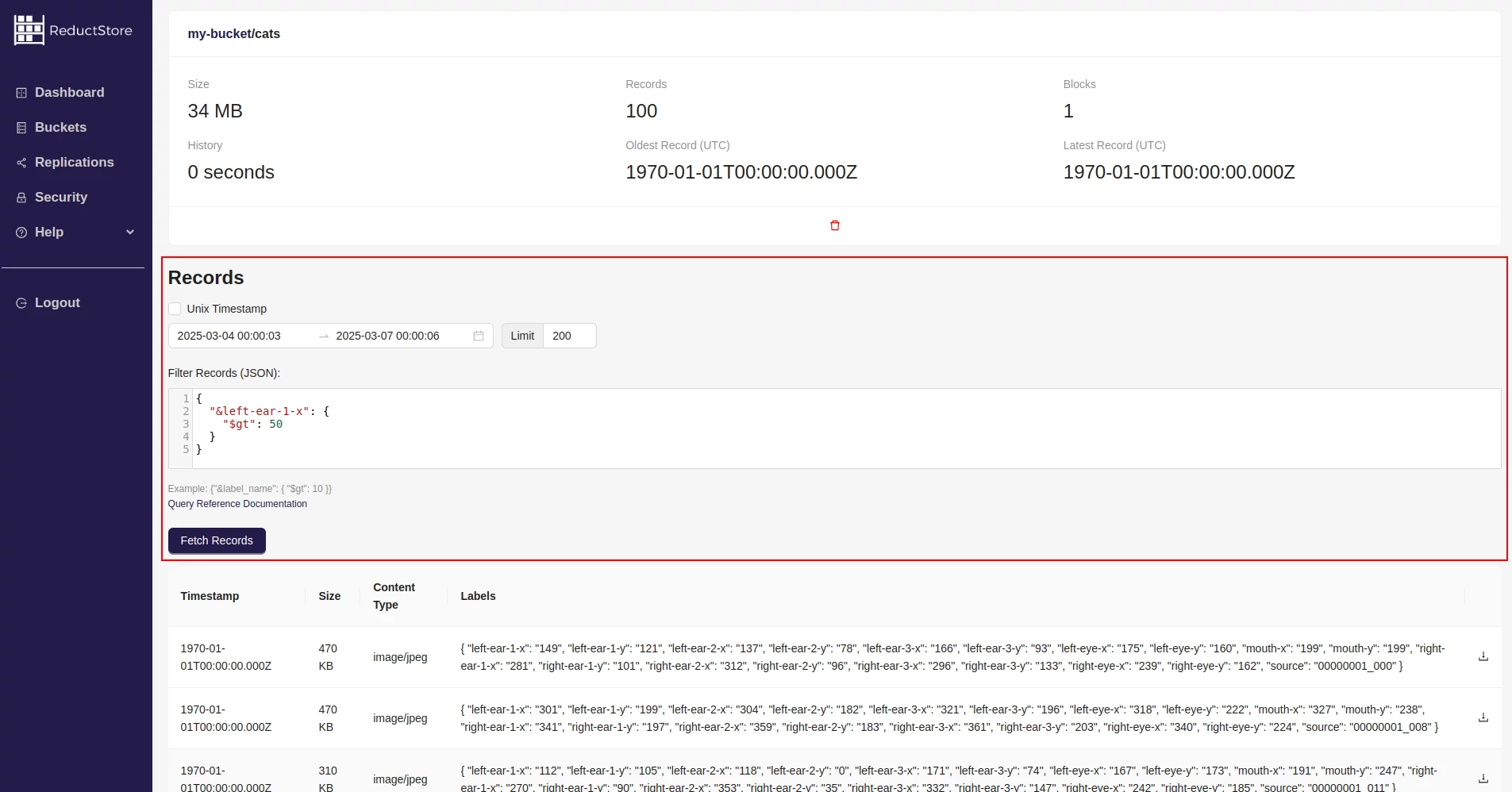
- Enter the time range in the date picker or manually in the input fields
- Click the "Fetch Records" button to execute the query
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
# Write a record to bucket "example-bucket" and entry "entry_1"
TIME=`date +%s000000`
curl -d "Some binary data" \
-H "${AUTH_HEADER}" \
-X POST -a ${API_PATH}/b/example-bucket/entry_1?ts=${TIME}
# Query data for a specific time range
STOP_TIME=`date +%s000000`
ID=`curl -H "${AUTH_HEADER}" \
-d '{"query_type": "QUERY", "start": '${TIME}', "stop": '${STOP_TIME}'}' \
-X POST -a "${API_PATH}/b/example-bucket/entry_1/q" | jq -r ".id"`
# Fetch the data (without batching)
curl -H "${AUTH_HEADER}" -X GET -a "${API_PATH}/b/example-bucket/entry_1?q=${ID}"
curl -H "${AUTH_HEADER}" -X GET -a "${API_PATH}/b/example-bucket/entry_1?q=${ID}"
Querying Record by Timestamp
The simplest way to query a record by its timestamp is to use the read method provided by the ReductStore SDKs or HTTP API:
- Python
- JavaScript
- Rust
- C++
- cURL
import time
import asyncio
from reduct import Client, Bucket
async def main():
# Create a client instance, then get or create a bucket
async with Client("http://127.0.0.1:8383", api_token="my-token") as client:
bucket: Bucket = await client.create_bucket("my-bucket", exist_ok=True)
ts = time.time()
await bucket.write(
"py-example",
b"Some binary data",
ts,
)
# Query records in the "py-example" entry of the bucket
async with bucket.read("py-example", ts) as record:
# Print meta information
print(f"Timestamp: {record.timestamp}")
print(f"Content Length: {record.size}")
print(f"Content Type: {record.content_type}")
print(f"Labels: {record.labels}")
# Read the record content
content = await record.read_all()
assert content == b"Some binary data"
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
import { Client } from "reduct-js";
import assert from "node:assert";
// Create a client instance, then get or create a bucket
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
const bucket = await client.getOrCreateBucket("bucket");
// Send a record to the "js-example" entry with the current timestamp in microseconds
const timestamp = BigInt(Date.now()) * 1000n;
let record = await bucket.beginWrite("js-example", timestamp);
await record.write("Some binary data");
// Query records in the "js-example" entry of the bucket
record = await bucket.beginRead("js-example", timestamp);
// Print meta information
console.log(`Timestamp: ${record.time}`);
console.log(`Content Length: ${record.size}`);
console.log(`Content Type: ${record.contentType}`);
console.log(`Labels: ${JSON.stringify(record.labels)}`);
// Read the record content
let content = await record.read();
assert(content.toString() === "Some binary data");
use std::time::SystemTime;
use bytes::Bytes;
use reduct_rs::{ReductClient, ReductError};
use tokio;
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a client instance, then get or create a bucket
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
let bucket = client.create_bucket("test").exist_ok(true).send().await?;
// Send a record to the "rs-example" entry with the current timestamp
let timestamp = SystemTime::now();
bucket
.write_record("rs-example")
.timestamp(timestamp)
.data("Some binary data")
.send()
.await?;
// Query record by timestamp
let record = bucket
.read_record("rs-example")
.timestamp(timestamp)
.send()
.await?;
println!("Timestamp: {:?}", record.timestamp());
println!("Content Length: {}", record.content_length());
println!("Content Type: {}", record.content_type());
println!("Labels: {:?}", record.labels());
// Read the record data
let data = record.bytes().await?;
assert_eq!(data, Bytes::from("Some binary data"));
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
using std::chrono_literals::operator ""s;
int main() {
// Create a client instance, then get or create a bucket
auto client = IClient::Build("http://127.0.0.1:8383", {.api_token="my-token"});
auto [bucket, create_err] = client->GetOrCreateBucket("my-bucket");
assert(create_err == Error::kOk);
// Send a record with labels and content type
IBucket::Time ts = IBucket::Time::clock::now();
auto err = bucket->Write("cpp-example", ts,[](auto rec) {
rec->WriteAll("Some binary data");
});
assert(err == Error::kOk);
// Query records in a time range
err = bucket->Read("cpp-example", ts, [](auto rec) {
// Print metadata
std::cout << "Timestamp: " << rec.timestamp.time_since_epoch().count() << std::endl;
std::cout << "Content Length: " << rec.size << std::endl;
std::cout << "Content Type: " << rec.content_type << std::endl;
std::cout << "Labels: " ;
for (auto& [key, value] : rec.labels) {
std::cout << key << ": " << value << ", ";
}
std::cout << std::endl;
// Read the content
auto [content, read_err] = rec.ReadAll();
assert(read_err == Error::kOk);
std::cout << "Content: " << content << std::endl;
assert(content == "Some binary data");
return true; // if false, the query will stop
});
assert(err == Error::kOk);
return 0;
}
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
# Write a record to bucket "example-bucket" and entry "entry_1"
TIME=`date +%s000000`
curl -d "Some binary data" \
-H "${AUTH_HEADER}" \
-X POST -a ${API_PATH}/b/example-bucket/entry_1?ts=${TIME}
# Fetch the record by timestamp
curl -H "${AUTH_HEADER}" -X GET -a "${API_PATH}/b/example-bucket/entry_1?ts=${TIME}"
Using Labels to Filter Data
Filtering data by labels is another common use case. You can use the when parameter to filter records based on labels.
ReductStore supports a wide range of operators for conditional queries, including equality, comparison, and logical operators. Refer to the Conditional Query Reference for more information.
For example, consider a data set with annotated photos of celebrities. We want to retrieve the first 10 photos of celebrities taken after 2006 with a score less than 4:
- Python
- JavaScript
- Rust
- C++
- CLI
- Web Console
- cURL
import time
import asyncio
from reduct import Client, Bucket
async def main():
# Create a client instance, then get or create a bucket
async with Client("http://127.0.0.1:8383", api_token="my-token") as client:
bucket: Bucket = await client.get_bucket("example-bucket")
# Query 10 photos from "imdb" entry which taken after 2006 with the face score less than 4
async for record in bucket.query(
"imdb",
limit=10,
when={
"&photo_taken": {"$gt": 2006},
"&face_score": {"$lt": 4},
},
):
print("Name", record.labels["name"])
print("Photo taken", record.labels["photo_taken"])
print("Face score", record.labels["face_score"])
_jpeg = await record.read_all()
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
import { Client } from "reduct-js";
// Create a client instance, then get or create a bucket
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
const bucket = await client.getBucket("example-bucket");
// Query 10 photos from "imdb" entry which taken after 2006 with the face score less than 4
for await (const record of bucket.query("imdb", undefined, undefined, {
limit: 10,
when: {
"&photo_taken": { $gt: 2006 },
"&face_score": { $lt: 4 },
},
})) {
console.log("Name", record.labels.name);
console.log("Photo taken", record.labels.photo_taken);
console.log("Face score", record.labels.face_score);
await record.readAsString();
}
use futures::StreamExt;
use reduct_rs::{condition, ReductClient, ReductError};
use tokio;
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a client instance, then get or create a bucket
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
let bucket = client
.create_bucket("example-bucket")
.exist_ok(true)
.send()
.await?;
// Query 10 photos from "imdb" entry which taken after 2006 with the face score less than 4
let query = bucket
.query("imdb")
.when(condition!({
"&photo_taken": {"$gt": 2006},
"&face_score": {"$gt": 4}
}))
.limit(10)
.send()
.await?;
tokio::pin!(query);
while let Some(record) = query.next().await {
let record = record?;
println!("Name: {:?}", record.labels().get("name"));
println!("Photo Taken: {:?}", record.labels().get("photo_taken"));
println!("Face Score: {:?}", record.labels().get("face_score"));
_ = record.bytes().await?;
}
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
using std::chrono_literals::operator ""s;
int main() {
// Create a client instance, then get or create a bucket
auto client = IClient::Build("http://127.0.0.1:8383", {.api_token="my-token"});
auto [bucket, create_err] = client->GetOrCreateBucket("example-bucket");
assert(create_err == Error::kOk);
// Query 10 photos from "imdb" entry which taken after 2006 with the face score less than 4
auto err = bucket->Query("imdb", std::nullopt, std::nullopt, {
.when=R"({
"&photo_taken": {"$gt": 2006},
"&name": {"$lt": 4}
})",
.limit = 10,
}, [](auto rec) {
std::cout << "Name: " << rec.labels["name"] << std::endl;
std::cout << "Photo Taken: " << rec.labels["photo_taken"] << std::endl;
std::cout << "Face Score: " << rec.labels["face_score"] << std::endl;
auto [_, read_err] = rec.ReadAll();
assert(read_err == Error::kOk);
return true; // if false, the query will stop
});
assert(err == Error::kOk);
return 0;
}
reduct-cli alias add local -L http://localhost:8383 -t "my-token"
# Query 10 photos from "imdb" entry which taken after 2006 with the face score less than 4
reduct-cli cp local/example-bucket ./export --when='{"&photo_taken": {"$gt": 2006}, "&face_score": {"$lt": 4}}' --limit 10 --with-meta
- Open the Web Console at
http://127.0.0.1:8383in your browser. - Enter the API token if the authorization is enabled.
- Select the bucket that contains the data you want to query:
- You will see a list of all the entries in the bucket
- Click on the entry you want to query
- On the entry page you will see the query panel:
- Enter the query condition in the "Filter Records (JSON)" input field
- Click the "Fetch Records" button to execute the query
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
# // Query 10 photos from "imdb" entry which taken after 2006 with the face score less than 4
ID=`curl -H "${AUTH_HEADER}" \
-d '{
"query_type": "QUERY",
"limit": 10,
"when": {
"&photo_taken": {"$gt": 2006},
"&face_score": {"$lt": 4}
}' -X POST -a "${API_PATH}/b/example-bucket/imdb/q" | jq -r ".id"`
# Fetch the data (without batching) until the end
curl -H "${AUTH_HEADER}" -X GET -a "${API_PATH}/b/example-bucket/imdb?q=${ID}" --output ./phot_1.jpeg
curl -H "${AUTH_HEADER}" -X GET -a "${API_PATH}/b/example-bucket/imdb?q=${ID}" --output ./phot_2.jpeg