ReductStore Bucket Guide
Buckets are the primary storage unit in ReductStore. They are used to group data entries and define the storage settings for the data. This guide will cover the concepts of buckets, their settings, and operations like creating, browsing, changing settings, and removing buckets.
Concepts
A bucket is a container used for data storage and serves as a logical grouping of data. Each bucket can contain multiple entries, with each entry representing a time-series dataset composed of time-stamped records. If you're familiar with databases, think of a bucket as a database, and entries as tables.
Given the nature of time-series data, ReductStore partitions data into blocks. Each block, stored in a separate file, contains a set of records. There are limits to the block size and the number of records it can hold. When a block reaches its limit, a new block is created to store additional data. This method allows ReductStore to store and access data efficiently. You can read more about blocks and records in the How Does It Work? document.
Unlike other blob storage or file systems, ReductStore has a flat hierarchy. It doesn't use folders or directories. Instead, all data is stored in entries, which are grouped by buckets.
Bucket Settings
Each bucket has settings that determine how data is stored and accessed. These settings include:
- Quota Type: You can choose between NONE, which means there is no quota, and FIFO (First In, First Out), where the oldest data is removed to make space for new data. The default setting is NONE.
- Quota Size: This represents the quota size in bytes. Only enforced with FIFO Quota.
- Max Block Size: This is the maximum allowable size of a block, in bytes. The default size is 64MB.
- Maximal Number of Records: This is the maximum number of records that can be contained in a block. The default number is 1024.
Quota Type
The quota type determines the method of quota enforcement and can be set to either NONE, FIFO or HARD.
NONE implies no quota, allowing data to be stored without any restrictions.
FIFO, short for first-in-first-out, enforces the quota by deleting the oldest block to accommodate new data once the quota is reached. ReductStore ensures that the data does not surpass the quota size, refusing to store new data if there's insufficient room.
HARD is a strict quota type that prevents data from being stored once the quota is reached. This setting is useful when you want to limit the amount of data stored in a bucket but don't want to delete old data.
Quota Size
The quota size defines the maximum size of the bucket in bytes. It's ignored if the quota type is set to NONE.
Max Block Size
The max block size determines the maximum size of a block in bytes. Once a block reaches this limit, a new block is created for storing additional data. A record's size isn't restricted by the block size. If a record exceeds the block size, it will be stored in the current block, and a new block will be created for the next record.
The default value is set at 64MB. Typically, there is no need to alter this unless your records exceed the default size. ReductStore pre-allocates the block size during the creation of a new block. As such, it improves performance when multiple records can be stored in a single block. We recommend to keep the block size large enough to store at least 1024 records.
Maximal Number of Records
The maximal number of records refers to the maximum number of records that can be stored in a block. When a block reaches this capacity, a new block is created for additional data. The default value is 1024. Generally, you don't need to adjust this unless you have numerous small records and an excess of blocks, which could impact search performance.
To optimize search performance, bear in mind that record searching consists of two steps:
- Locating the block that contains the record. This search time is O(log(n)), where n represents the number of blocks.
- Finding the record within the block. This search time is O(m), with m representing the number of records in the block.
If there are too many blocks, the time spent searching for a block could exceed the time spent searching for the record within the block. In such cases, consider increasing the maximal number of records to reduce the total number of blocks.
Bucket Operations
Here you will find examples of how to create, browse, change settings, and remove buckets using the ReductStore SDKs, CLI client, Web Console, and REST API.
Pay attention that all the examples are written for a local ReductStore instance available at http://127.0.0.1:8383 with API token my-token.
For more information on how to set up a local ReductStore instance, refer to the Getting Started guide.
Creating a Bucket
A bucket can be created using the SDKs, CLI client, Web Console, or REST API. The bucket name must be unique within the store, and a client must have full access permission if the authentication is enabled. Provisioning a bucket with environment variables is also possible. Refer to the example below:
- CLI
- Web Console
- Python
- JavaScript
- Go
- Rust
- C++
- cURL
- Provisioning
reduct-cli alias add local -L http://localhost:8383 -t "my-token"
reduct-cli bucket create local/my-bucket --quota-type FIFO --quota-size 1GB
- Open the Web Console at
http://127.0.0.1:8383in your browser. - Enter the API token if the authorization is enabled.
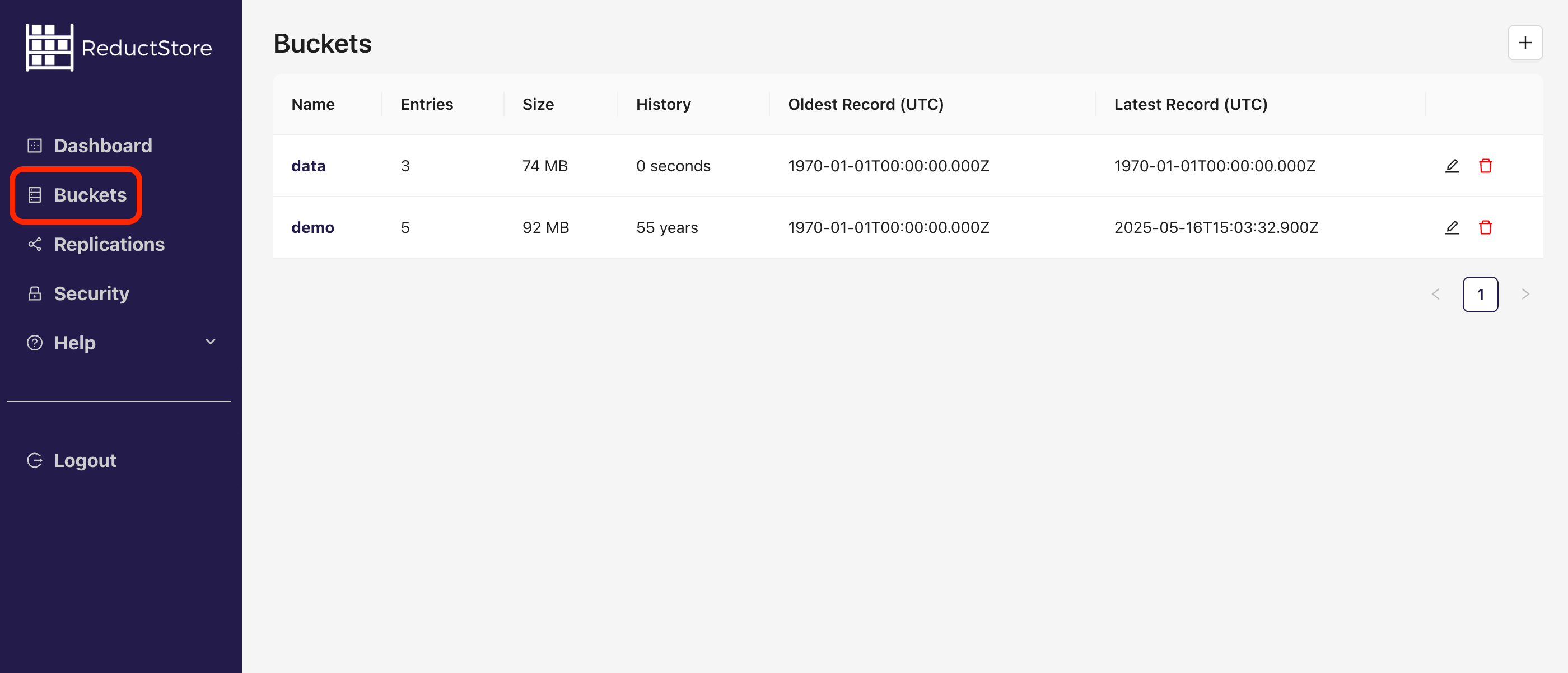
- Click on the "Buckets" tab in the left sidebar.
- Click on the plus icon in the top right corner to create a new bucket:
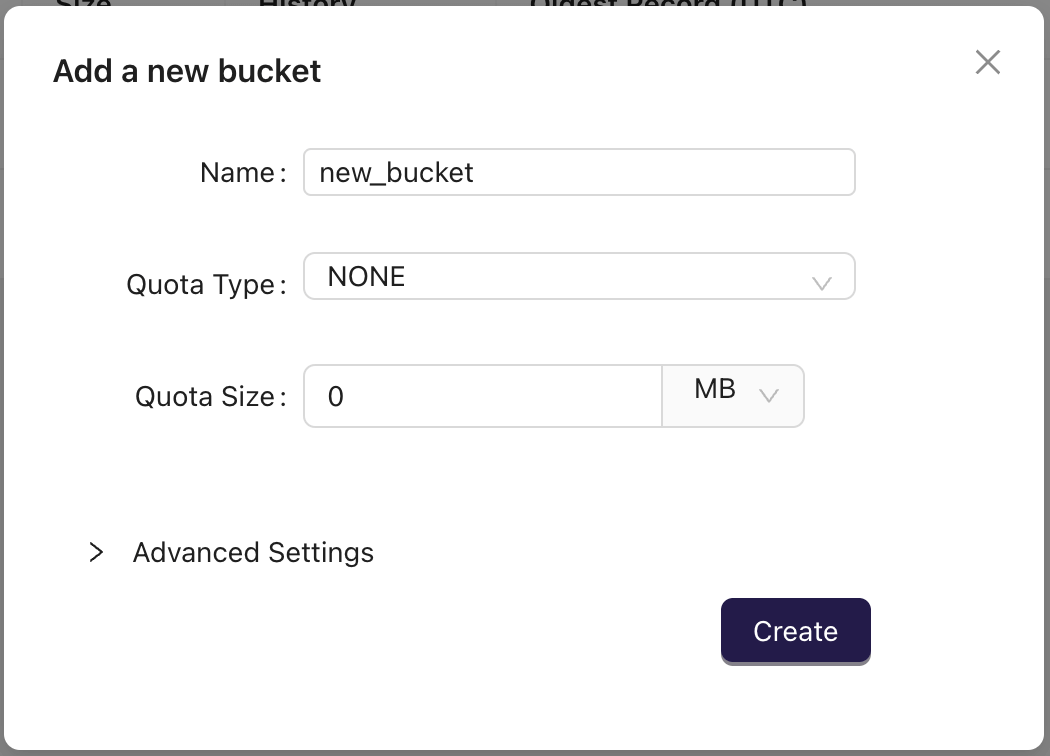
- In the "Add a new bucket" dialog, enter the bucket name and settings.
- Click on the "Create" button to create the bucket:
from reduct import Client, BucketSettings, QuotaType
async def create_bucket():
# Create a client with the base URL and API token
async with Client("http://localhost:8383", api_token="my-token") as client:
# Create a bucket with the name "my-bucket" and a FIFO quota of 1GB
settings = BucketSettings(
quota_type=QuotaType.FIFO,
quota_size=1000_000_000,
)
bucket = await client.create_bucket("my-bucket", settings, exist_ok=True)
assert bucket.name == "my-bucket"
if __name__ == "__main__":
import asyncio
asyncio.run(create_bucket())
import { Client, QuotaType } from "reduct-js";
import assert from "node:assert";
// Create a new client with the server URL and an API token
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
// Create a bucket with the name "my-bucket" and a FIFO quota of 1GB
let settings = {
quotaType: QuotaType.FIFO,
quotaSize: 1000_000_000n,
};
const bucket = await client.getOrCreateBucket("bucket", settings);
assert(bucket.name === "bucket");
package main
import (
"context"
reduct "github.com/reductstore/reduct-go"
model "github.com/reductstore/reduct-go/model"
)
func main() {
// Create a client using the server URL and API token
client := reduct.NewClient("http://localhost:8383", reduct.ClientOptions{
APIToken: "my-token",
})
// Create a bucket with the name "my-bucket" and a FIFO quota of 1GB
settings := model.NewBucketSettingBuilder().
WithQuotaType(model.QuotaTypeFifo).
WithQuotaSize(1_000_000_000).
Build()
bucket, err := client.CreateOrGetBucket(context.Background(), "my-bucket", &settings)
if err != nil {
panic(err)
}
if bucket.Name != "my-bucket" {
panic("Bucket was not created or retrieved correctly")
}
}
use reduct_rs::{QuotaType, ReductClient, ReductError};
use tokio;
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a new client with the API URL and API token
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
// Create a bucket with the name "my-bucket" and a FIFO quota of 1GB
let bucket = client
.create_bucket("my-bucket")
.quota_type(QuotaType::FIFO)
.quota_size(1_000_000_000)
.exist_ok(true)
.send()
.await?;
assert_eq!(bucket.name(), "my-bucket");
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
int main() {
// Create a client with the server URL
auto client = IClient::Build("http://127.0.0.1:8383", {
.api_token = "my-token"
});
// Create a bucket with the name "my-bucket" and a FIFO quota of 1GB
IBucket::Settings settings;
settings.quota_type = IBucket::QuotaType::kFifo;
settings.quota_size = 1'000'000'000;
auto [bucket, create_err] = client->GetOrCreateBucket("my-bucket", settings);
assert(create_err == Error::kOk);
assert(bucket->GetInfo().result.name == "my-bucket");
}
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
curl -X POST \
-d '{"quota_type":"FIFO", "quota_size":1000000000}' \
-H "${AUTH_HEADER}" \
-a "${API_PATH}"/b/my_data
version: "3"
services:
reductstore:
image: reduct/store:latest
ports:
- "8383:8383"
volumes:
- ./data:/data
environment:
- RS_API_TOKEN=my-api-token
- RS_BUCKET_1_NAME=my-bucket
- RS_BUCKET_1_QUOTA_TYPE=FIFO
- RS_BUCKET_1_QUOTA_SIZE=1GB
Browse Buckets
You might want to view the list of buckets in your store or see the details of a specific bucket. This can be done by using the SDKs, CLI client, Web Console, or REST API. For listing all buckets, a client must have a valid access token if the authorization is enabled.
- CLI
- Web Console
- Python
- JavaScript
- Go
- Rust
- C++
- cURL
reduct-cli alias add local -L http://localhost:8383 -t "my-token"
reduct-cli bucket ls local --full
# Output:
#| Name | Entries | Size | Oldest record (UTC) | Latest record (UTC) |
#|-------------------|---------|----------|--------------------------|--------------------------|
#| example-bucket | 3 | 30.7 GB | 1970-01-01T00:00:00.000Z | 1970-01-01T00:00:00.060Z |
reduct-cli bucket show local/example-bucket --full
# Output:
#Name: datasets Quota Type: NONE
#Entries: 3 Quota Size: 0 B
#Size: 30.7 GB Max. Block Size: 64.0 MB
#Oldest Record (UTC): 1970-01-01T00:00:00.000Z Max. Block Records: 256
#Latest Record (UTC): 1970-01-01T00:00:00.060Z
#
#| Name | Records | Blocks | Size | Oldest Record (UTC) | Latest Record (UTC) |
#|----------------|---------|--------|---------|--------------------------|--------------------------|
#| cats | 9993 | 40 | 2.0 GB | 1970-01-01T00:00:00.000Z | 1970-01-01T00:00:00.016Z |
#| imdb | 46641 | 459 | 28.7 GB | 1970-01-01T00:00:00.000Z | 1970-01-01T00:00:00.046Z |
#| mnist_training | 60000 | 236 | 17.5 MB | 1970-01-01T00:00:00.000Z | 1970-01-01T00:00:00.060Z |
- Open the Web Console at
http://127.0.0.1:8383in your browser. - Enter the API token if the authorization is enabled.
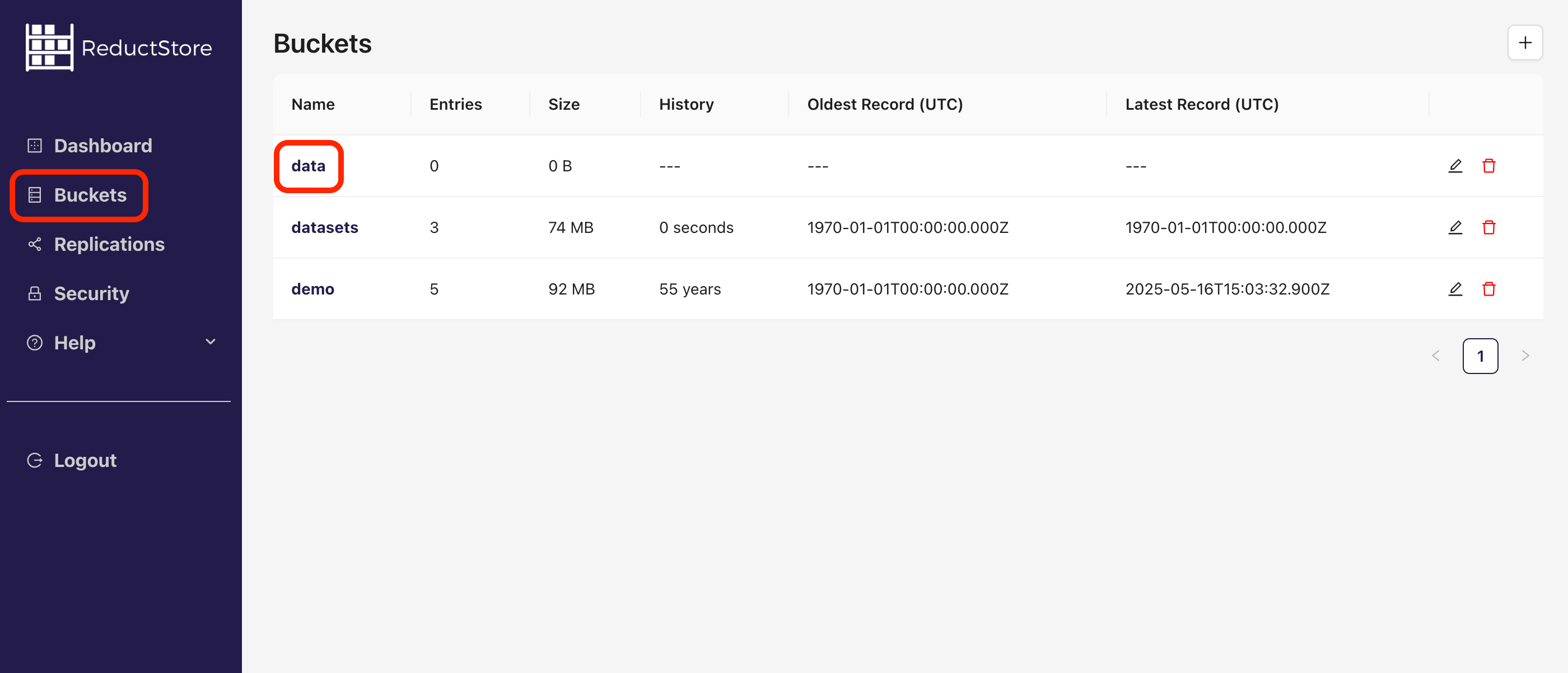
- Click on the "Buckets" tab in the left sidebar.
- You will see a list of all buckets in the store.
- Click on a specific bucket to view its details:
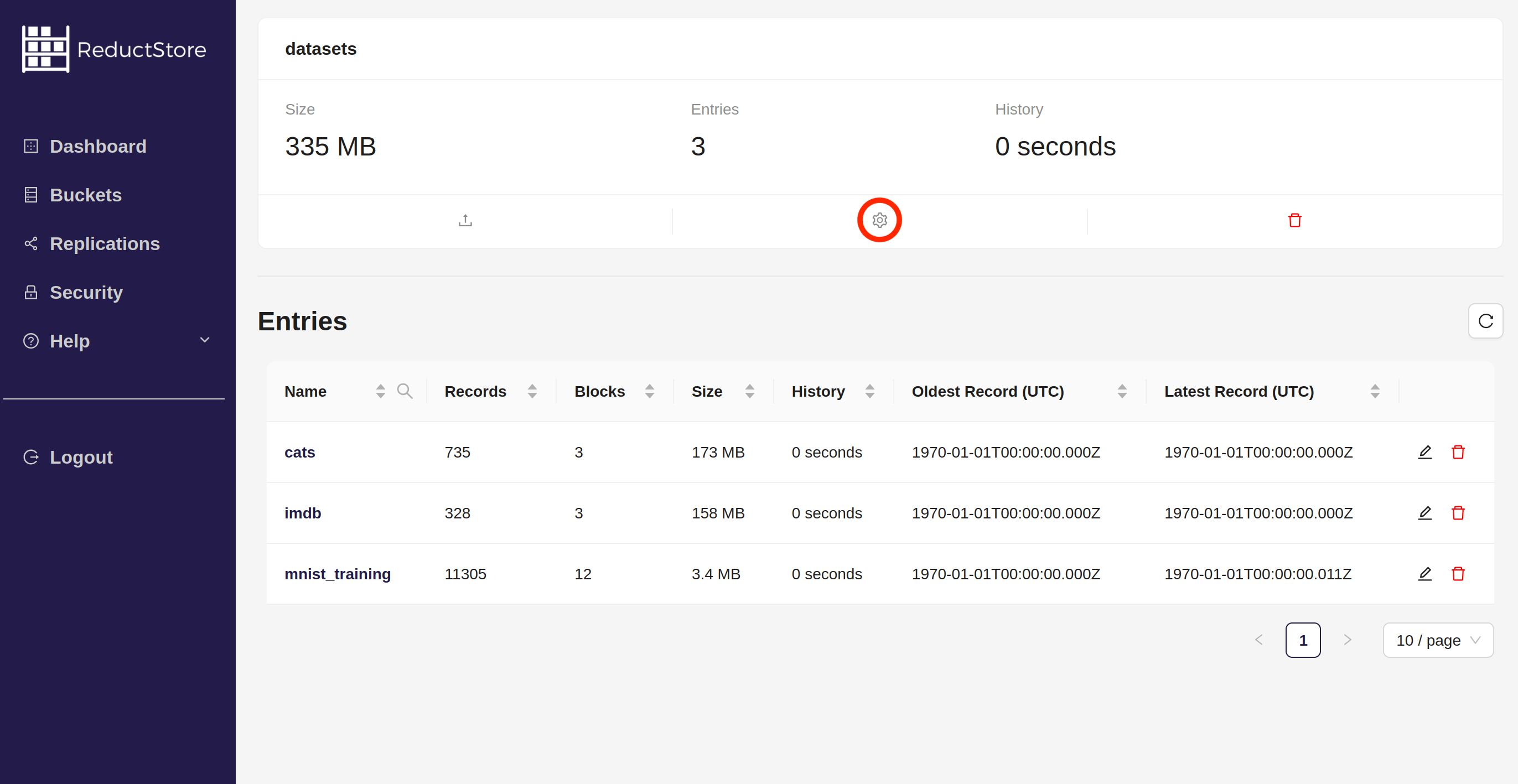
- You can see the bucket settings by clicking on the cog icon(⚙️) in the bucket panel:
from typing import List
from reduct import Client, Bucket, BucketInfo
async def browse_buckets():
# Create a client with the base URL and API token
async with Client("http://localhost:8383", api_token="my-token") as client:
# Browse all buckets and print their information
buckets: List[BucketInfo] = await client.list()
for info in buckets:
print(f"Bucket: {info.name}")
print(f"Size: {info.size}")
print(f"Entry Count: {info.entry_count}")
print(f"Oldest Record: {info.oldest_record}")
print(f"Latest Record: {info.latest_record}")
# Get information about a specific bucket
bucket: Bucket = await client.get_bucket("example-bucket")
info = await bucket.get_full_info()
print(f"Bucket settings: {info.settings}")
for entry in info.entries:
print(f"Entry: {entry.name}")
print(f"Size: {entry.size}")
print(f"Oldest Record: {entry.oldest_record}")
print(f"Latest Record: {entry.latest_record}")
if __name__ == "__main__":
import asyncio
asyncio.run(browse_buckets())
import { Client } from "reduct-js";
// Create a new client with the server URL and an API token
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
// Browse the list of buckets and print their information
for (const info of await client.getBucketList()) {
console.log(`Bucket: ${info.name}`);
console.log(`Size: ${info.size}`);
console.log(`Entry Count: ${info.entryCount}`);
console.log(`Oldest Record: ${info.oldestRecord}`);
console.log(`Latest Record: ${info.latestRecord}`);
}
// Get information about a specific bucket
const bucket = await client.getBucket("example-bucket");
const settings = await bucket.getSettings();
console.log(`Settings: ${settings}`);
for (const info of await bucket.getEntryList()) {
console.log(`Entry: ${info.name}`);
console.log(`Size: ${info.size}`);
console.log(`Oldest Record: ${info.oldestRecord}`);
console.log(`Latest Record: ${info.latestRecord}`);
}
package main
import (
"context"
reduct "github.com/reductstore/reduct-go"
)
func main() {
// Create a client and use the base URL and API token
client := reduct.NewClient("http://localhost:8383", reduct.ClientOptions{
APIToken: "my-token",
})
// Browse all buckets and print their information
buckets, err := client.GetBuckets(context.Background())
if err != nil {
panic(err)
}
for _, info := range buckets {
println("Bucket:", info.Name)
println("Size:", info.Size)
println("Entry Count:", info.EntryCount)
println("Oldest Record:", info.OldestRecord)
println("Latest Record:", info.LatestRecord)
}
// Get information about a specific bucket
bucket, err := client.GetBucket(context.Background(), "example-bucket")
if err != nil {
panic(err)
}
info, err := bucket.GetFullInfo(context.Background())
if err != nil {
panic(err)
}
println("Quota Type:", info.Settings.QuotaType)
for _, entry := range info.Entries {
println("Entry:", entry.Name)
println("Size:", entry.Size)
println("Oldest Record:", entry.OldestRecord)
println("Latest Record:", entry.LatestRecord)
}
}
use reduct_rs::{Bucket, ReductClient, ReductError};
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a new client with the API URL and API token
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
// Browse all buckets and print their information
let buckets = client.bucket_list().await?.buckets;
for info in buckets {
println!("Bucket: {}", info.name);
println!("Size: {}", info.size);
println!("Entry count: {}", info.entry_count);
println!("Oldest Record: {:?}", info.oldest_record);
println!("Latest Record: {:?}", info.latest_record);
}
// Get information about a specific bucket
let bucket: Bucket = client.get_bucket("example-bucket").await?;
let settings = bucket.settings().await?;
println!("Settings: {:?}", settings);
for entry in bucket.entries().await? {
println!("Entry: {:?}", entry.name);
println!("Size: {:?}", entry.size);
println!("Oldest Record: {:?}", entry.oldest_record);
println!("Latest Record: {:?}", entry.latest_record);
}
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
std::string PrintTime(std::chrono::system_clock::time_point time) {
auto now_time_t = std::chrono::system_clock::to_time_t(time);
auto now_tm = std::localtime(&now_time_t);
char buf[32];
std::strftime(buf, sizeof(buf), "%Y-%m-%d %H:%M:%S", now_tm);
return buf;
}
int main() {
// Create a client with the server URL
auto client = IClient::Build("http://127.0.0.1:8383", {
.api_token = "my-token"
});
// Browse all buckets and print their information
auto [list, list_err] = client->GetBucketList();
assert(list_err == Error::kOk);
for (const auto &bucket: list) {
std::cout << "Bucket: " << bucket.name << std::endl;
std::cout << "Size: " << bucket.size << std::endl;
std::cout << "Entry count: " << bucket.entry_count << std::endl;
std::cout << "Latest Record: " << PrintTime(bucket.latest_record) << std::endl;
std::cout << "Oldest Record: " << PrintTime(bucket.oldest_record) << std::endl;
}
// Get information about a specific bucket
auto [bucket, get_err] = client->GetBucket("example-bucket");
assert(get_err == Error::kOk);
std::cout << "Bucket Settings: " << bucket->GetSettings().result << std::endl;
for (const auto &entry: bucket->GetEntryList().result) {
std::cout << "Entry: " << entry.name << std::endl;
std::cout << "Size: " << entry.size << std::endl;
std::cout << "Latest Record: " << PrintTime(entry.latest_record) << std::endl;
std::cout << "Oldest Record: " << PrintTime(entry.oldest_record) << std::endl;
}
return 0;
}
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
printf "Browse all buckets:\n"
curl -X GET \
-H "${AUTH_HEADER}" \
-a "${API_PATH}"/list
printf "\nBrowse a specific bucket:\n"
curl -X GET \
-H "${AUTH_HEADER}" \
-a "${API_PATH}"/b/my-bucket
Changing Bucket Settings
Bucket settings can be modified using the SDKs, CLI client, Web Console, or REST API. A client must have full access permission to change the settings if the authorization is enabled. The settings that can be modified include the quota type, quota size, max block size, and maximal number of records. You cannot change the bucket name.
- CLI
- Web Console
- Python
- JavaScript
- Go
- Rust
- C++
- cURL
reduct-cli alias add local -L http://localhost:8383 -t "my-token"
# Change the quota size of the bucket
reduct-cli bucket update local/example-bucket --quota-size 10GB
- Open the Web Console at
http://127.0.0.1:8383in your browser. - Enter the API token if the authorization is enabled.
- Click on the "Buckets" tab in the left sidebar.
- You will see a list of all buckets in the store.
- Click on a specific bucket in the list:
- Open the bucket settings by clicking on cog icon(⚙️) in the bucket panel:
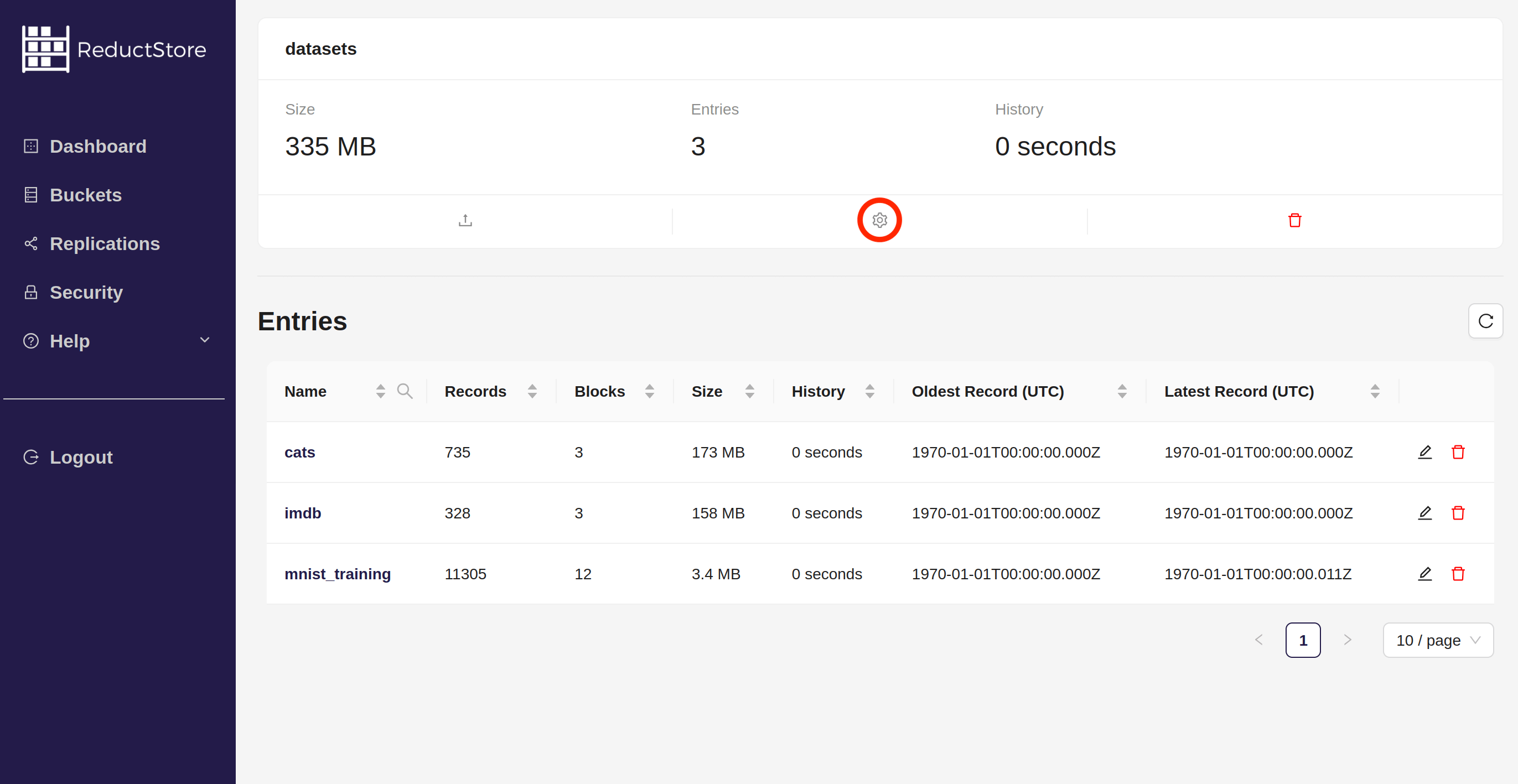
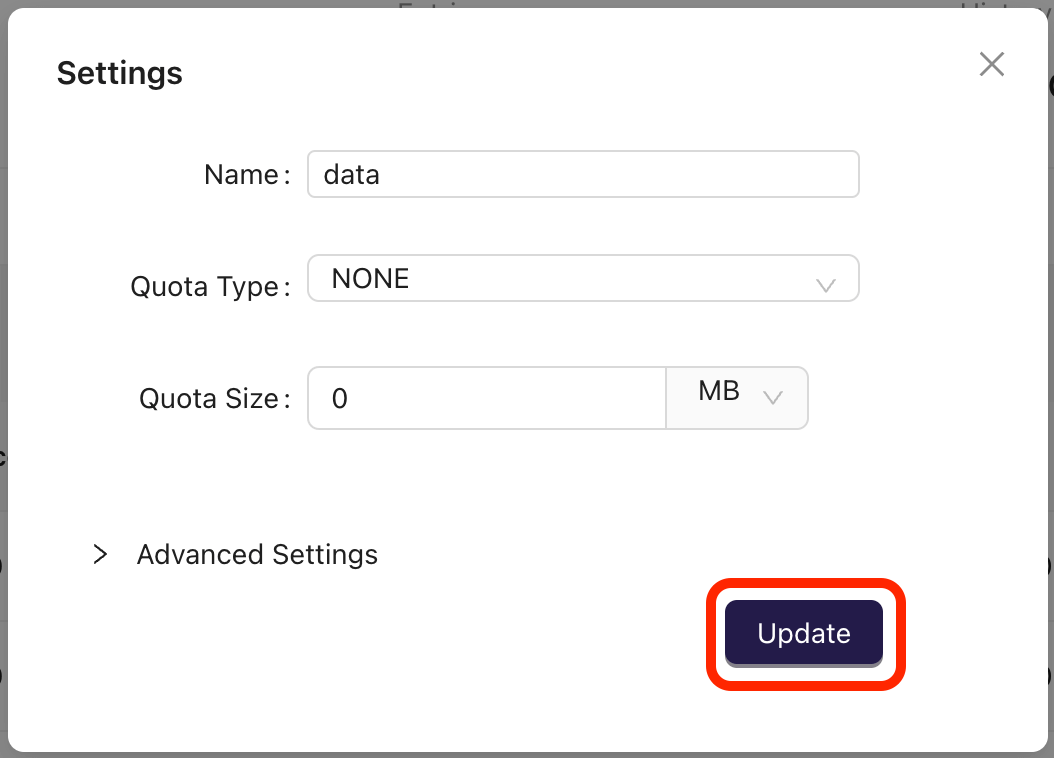
- Modify the settings as needed and click on the Update button:
from reduct import Client, BucketSettings, QuotaType
async def change_bucket():
# Create a client with the base URL and API token
async with Client("http://localhost:8383", api_token="my-token") as client:
# Get an existing bucket
bucket = await client.get_bucket("example-bucket")
# Change the quota size of the bucket to 5GB
new_settings = BucketSettings(quota_size=5000_000_000)
await bucket.set_settings(new_settings)
assert (await bucket.get_settings()).quota_size == 5000_000_000
if __name__ == "__main__":
import asyncio
asyncio.run(change_bucket())
import { Client } from "reduct-js";
import assert from "node:assert";
// Create a new client with the server URL and an API token
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
// Get an existing bucket
const bucket = await client.getBucket("example-bucket");
// Change the quota size of the bucket to 5GB
let new_settings = {
quotaSize: 5000_000_000n,
};
await bucket.setSettings(new_settings);
assert((await bucket.getSettings()).quotaSize === 5000_000_000n);
package main
import (
"context"
reduct "github.com/reductstore/reduct-go"
model "github.com/reductstore/reduct-go/model"
)
func main() {
// Create a client and use the base URL and API token
client := reduct.NewClient("http://localhost:8383", reduct.ClientOptions{
APIToken: "my-token",
})
// Get an existing bucket
bucket, err := client.GetBucket(context.Background(), "example-bucket")
if err != nil {
panic(err)
}
// Change the quota size of the bucket to 5GB
newSettings := model.NewBucketSettingBuilder().
WithQuotaType(model.QuotaTypeFifo).
WithQuotaSize(5_000_000_000).
Build()
err = bucket.SetSettings(context.Background(), newSettings)
if err != nil {
panic(err)
}
settings, err := bucket.GetSettings(context.Background())
if err != nil {
panic(err)
}
if settings.QuotaSize != 5_000_000_000 {
panic("Bucket settings were not updated correctly")
}
}
use reduct_rs::{BucketSettings, ReductClient, ReductError};
use tokio;
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a new client with the API URL and API token
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
// Get an existing bucket
let bucket = client.get_bucket("example-bucket").await?;
// Change the quota size of the bucket to 5GB
let new_settings = BucketSettings {
quota_size: Some(5_000_000_000),
..BucketSettings::default()
};
bucket.set_settings(new_settings).await?;
assert_eq!(bucket.settings().await?.quota_size, Some(5_000_000_000));
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
int main() {
// Create a client with the server URL
auto client = IClient::Build("http://127.0.0.1:8383", {
.api_token = "my-token"
});
// Get an existing bucket
auto [bucket, get_err] = client->GetBucket("example-bucket");
assert(get_err == Error::kOk);
// Change the quota size of the bucket to 5GB
IBucket::Settings new_settings;
new_settings.quota_size = 5'000'000'000;
auto change_err = bucket->UpdateSettings(new_settings);
assert(change_err == Error::kOk);
assert(bucket->GetSettings().result.quota_size == 5'000'000'000);
}
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
# Change the quota size of the bucket
curl -X UPDATE \
-d '{"quota_size":5000000000}' \
-H "${AUTH_HEADER}" \
-a "${API_PATH}"/b/my_data
Renaming a Bucket
A bucket can be renamed using the SDKs, CLI client, Web Console, or REST API. A client must have full access permission to rename a bucket if the authorization is enabled.
- CLI
- Web Console
- Python
- JavaScript
- Go
- Rust
- C++
- cURL
reduct-cli alias add local -L http://localhost:8383 -t "my-token"
reduct-cli bucket rename local/bucket-to-rename new-name
- Open the Web Console at
http://127.0.0.1:8383in your browser. - Enter the API token if the authorization is enabled.
- Click on the "Buckets" tab in the left sidebar.
- You will see a list of all buckets in the store.
- Click on the edit icon in the bucket panel:
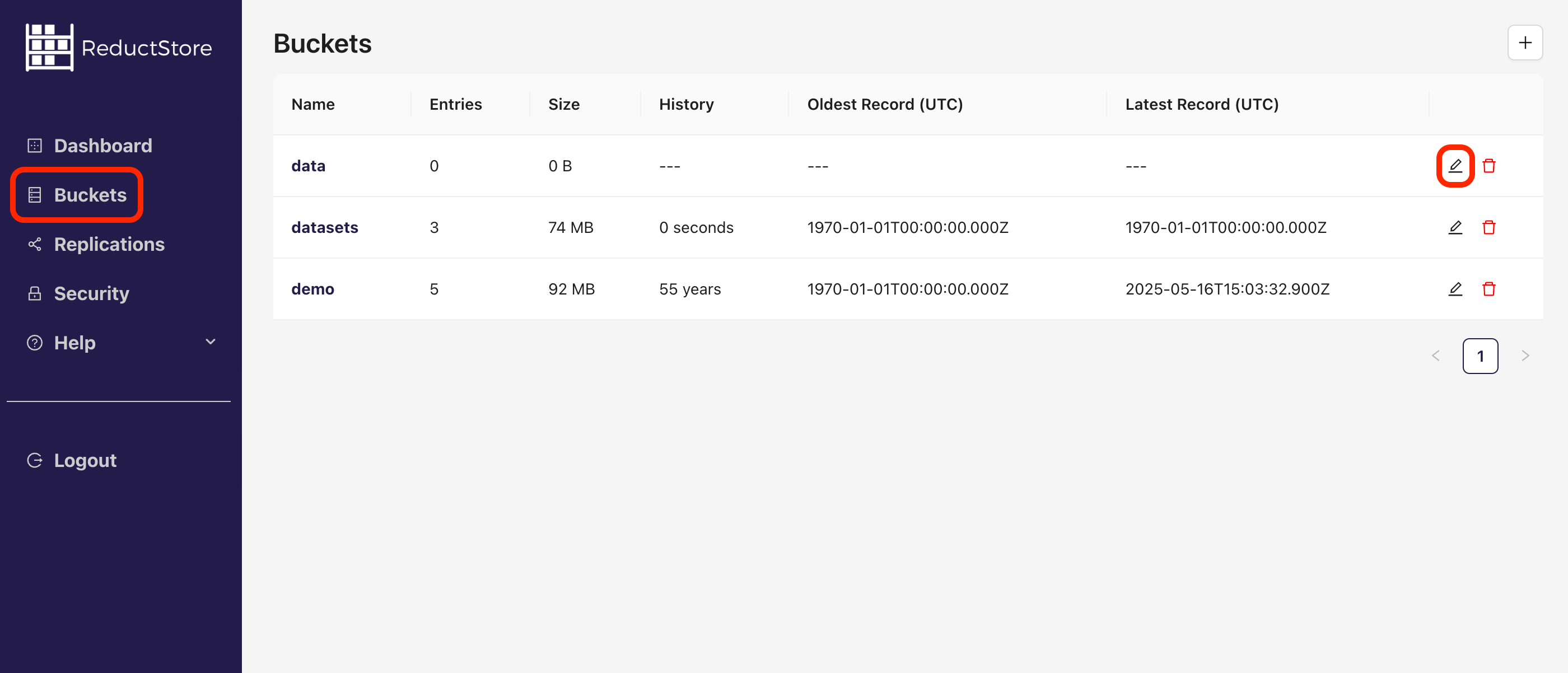
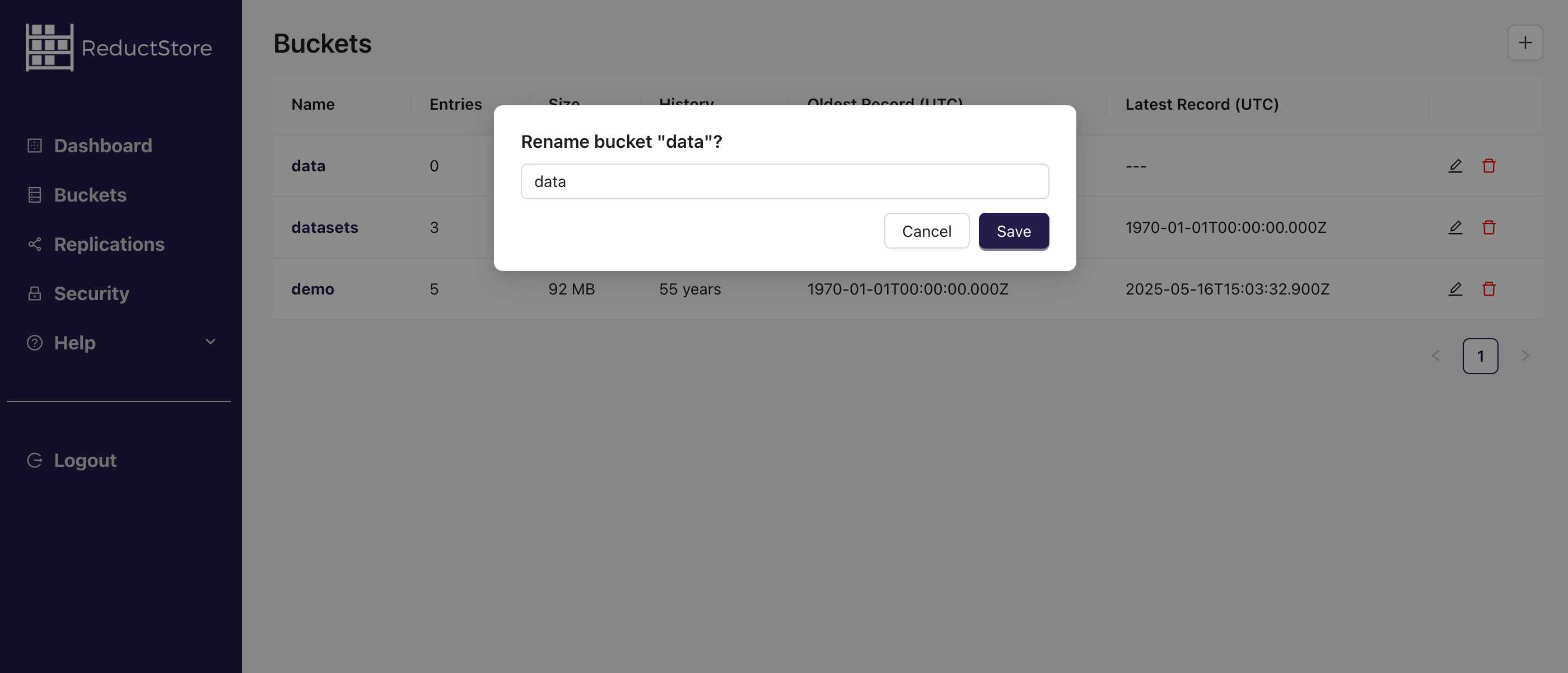
- Rename the bucket and click on the Save button:
from reduct import Client, ReductError
async def rename_bucket():
# Create a client with the base URL and API token
async with Client("http://127.0.0.1:8383", api_token="my-token") as client:
# Rename the bucket with the name "bucket-to-rename"
bucket = await client.get_bucket("bucket-to-rename")
await bucket.rename("bucket-renamed")
# Check that the bucket was renamed
assert await client.get_bucket("bucket-renamed")
try:
await client.get_bucket("bucket-to-rename")
except ReductError as e:
# The bucket should not exist anymore
assert e.status_code == 404
if __name__ == "__main__":
import asyncio
asyncio.run(rename_bucket())
import { Client } from "reduct-js";
import assert from "node:assert";
// Create a new client with the server URL and an API token
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
// Rename the bucket 'bucket-to-rename' to 'bucket-renamed'
const bucket = await client.getBucket("bucket-to-rename");
await bucket.rename("bucket-renamed");
// Check that the bucket was renamed
assert(await client.getBucket("bucket-renamed"));
try {
await client.getBucket("bucket-to-rename");
} catch (e) {
assert(e.status === 404);
}
package main
import (
"context"
reduct "github.com/reductstore/reduct-go"
)
func main() {
// Create a client and use the base URL and API token
client := reduct.NewClient("http://localhost:8383", reduct.ClientOptions{
APIToken: "my-token",
})
// Rename the bucket with the name "bucket-to-rename"
bucket, err := client.GetBucket(context.Background(), "bucket-to-rename")
if err != nil {
panic(err)
}
err = bucket.Rename(context.Background(), "bucket-renamed")
if err != nil {
panic(err)
}
// Check that the bucket was renamed
_, err = client.GetBucket(context.Background(), "bucket-renamed")
if err != nil {
panic(err)
}
}
use reduct_rs::{ReductClient, ReductError};
use tokio;
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a new client with the API URL and API token
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
// Get the bucket 'example-bucket'
let bucket = client.get_bucket("example-bucket").await?;
// Rename the entry 'entry_1' to 'entry_2'
bucket.rename_entry("entry_1", "entry_2").await?;
// Check that the entry was renamed
let entries = bucket.entries().await?;
let entry_names: Vec<&str> = entries.iter().map(|entry| entry.name.as_str()).collect();
assert!(entry_names.contains(&"entry_2"));
assert!(!entry_names.contains(&"entry_1"));
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
int main() {
// Create a client with the server URL
auto client = IClient::Build("http://127.0.0.1:8383", {
.api_token = "my-token"
});
// Rename the bucket with the name "bucket-to-rename" to "bucket-renamed"
auto [bucket, get_err] = client->GetBucket("bucket-to-rename");
assert(get_err == Error::kOk);
auto rename_err = bucket->Rename("bucket-renamed");
assert(rename_err == Error::kOk);
// Check that the old name no longer exists
auto [_, get_err2] = client->GetBucket("bucket-to-rename");
assert(get_err2.code == 404);
// Check that the new name exists
auto [_, get_err3] = client->GetBucket("bucket-renamed");
assert(get_err3 == Error::kOk);
}
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
curl -X PUT \
-H "${AUTH_HEADER}" \
-a "${API_PATH}/b/bucket-to-rename/rename" \
-H "Content-Type: application/json" \
-d '{"new_name": "bucket-renamed"}'
Removing a Bucket
A bucket can be deleted using the SDKs, CLI client, Web Console, or REST API. A client must have full access permission to delete a bucket if the authorization is enabled.
- CLI
- Web Console
- Python
- JavaScript
- Go
- Rust
- C++
- cURL
reduct-cli alias add local -L http://localhost:8383 -t "my-token"
# Remove the bucket without confirmation
reduct-cli bucket rm local/bucket-to-remove -y
- Open the Web Console at
http://127.0.0.1:8383in your browser. - Enter the API token if the authorization is enabled.
- Click on the "Buckets" tab in the left sidebar.
- You will see a list of all buckets in the store.
- Click on a specific bucket in the list:
- Click on the Trash icon in the bucket panel:
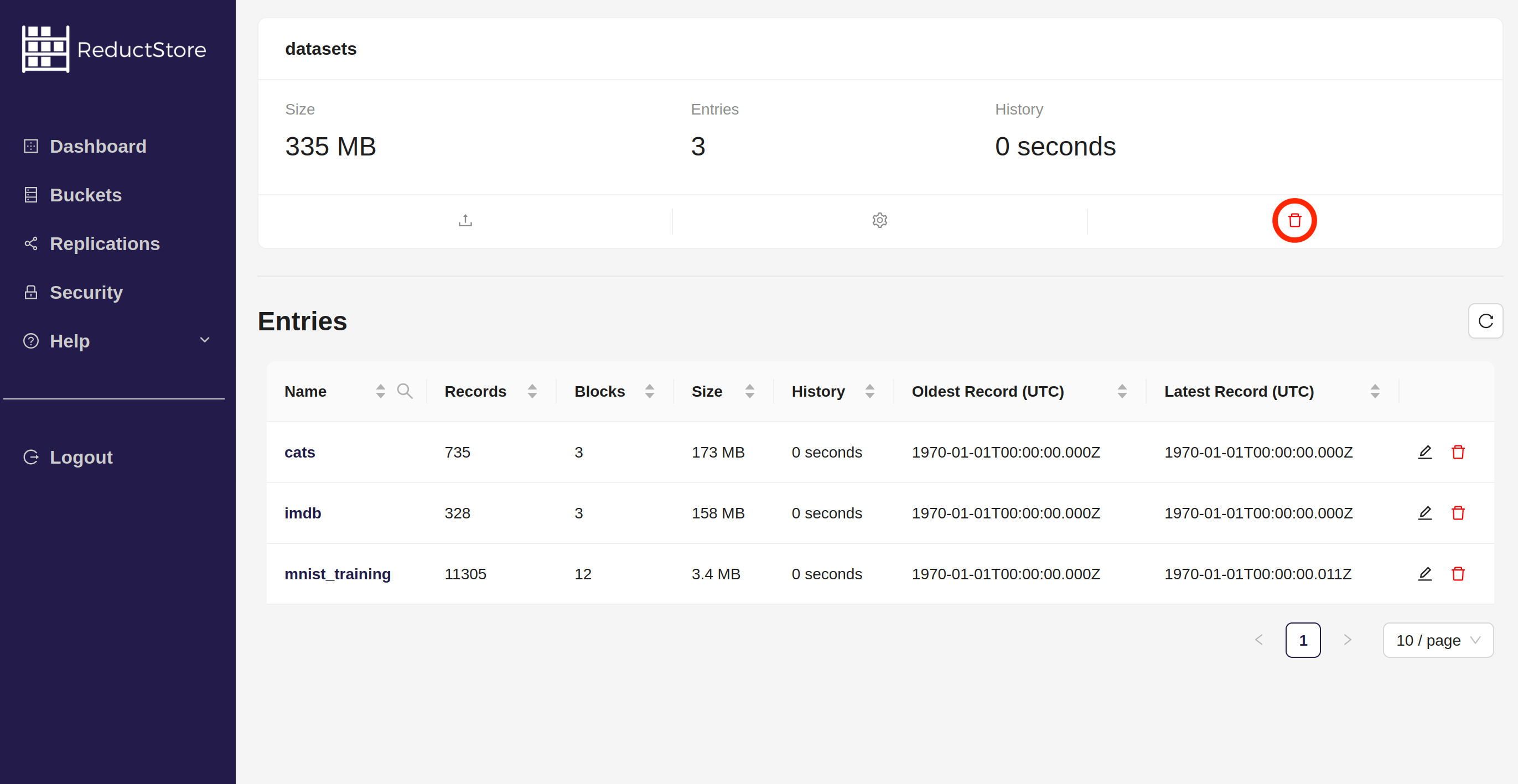
- Confirm the deletion by typing the bucket name and clicking on the Remove button:

import asyncio
from reduct import Client, ReductError
async def remove_bucket():
# Create a client with the base URL and API token
async with Client("http://127.0.0.1:8383", api_token="my-token") as client:
# Remove the bucket with the name "bucket-to-remove"
bucket = await client.get_bucket("bucket-to-remove")
await bucket.remove()
# Check that the bucket no longer exists
try:
await client.get_bucket("bucket-to-remove")
except ReductError as e:
# The bucket should not exist anymore or still be in the process of being removed
assert e.status_code in [404, 409]
if __name__ == "__main__":
asyncio.run(remove_bucket())
import { Client } from "reduct-js";
import assert from "node:assert";
// Create a new client with the server URL and an API token
const client = new Client("http://127.0.0.1:8383", { apiToken: "my-token" });
// Remove the bucket with the name "bucket-to-remove"
const bucket = await client.getBucket("bucket-to-remove");
await bucket.remove();
// Check that the bucket no longer exists or is in the process of being removed
try {
await client.getBucket("bucket-to-remove");
} catch (e) {
const status = e?.status ?? e?.statusCode;
assert(status === 404 || status === 409);
}
package main
import (
"context"
reduct "github.com/reductstore/reduct-go"
)
func main() {
// Create a client and use the base URL and API token
client := reduct.NewClient("http://localhost:8383", reduct.ClientOptions{
APIToken: "my-token",
})
// Remove the bucket with the name "bucket-to-remove"
bucket, err := client.GetBucket(context.Background(), "bucket-to-remove")
if err != nil {
panic(err)
}
err = bucket.Remove(context.Background())
if err != nil {
panic(err)
}
// Check that the bucket no longer exists or is in the process of being removed
_, err = client.GetBucket(context.Background(), "bucket-to-remove")
if err == nil {
panic("Bucket should not exist anymore")
}
}
use reduct_rs::{ErrorCode, ReductClient, ReductError};
use tokio;
#[tokio::main]
async fn main() -> Result<(), ReductError> {
// Create a new client with the API URL and API token
let client = ReductClient::builder()
.url("http://127.0.0.1:8383")
.api_token("my-token")
.build();
// Remove the bucket "bucket-to-remove"
let bucket = client.get_bucket("bucket-to-remove").await?;
bucket.remove().await?;
// Check that the bucket no longer exists or is in the process of being removed
let status_code = client.get_bucket("bucket-to-remove").await.err().unwrap().status;
assert!(
status_code == ErrorCode::NotFound || status_code == ErrorCode::Conflict
);
Ok(())
}
#include <reduct/client.h>
#include <iostream>
#include <cassert>
#include <thread>
#include <chrono>
using reduct::IBucket;
using reduct::IClient;
using reduct::Error;
int main() {
// Create a client with the server URL
auto client = IClient::Build("http://127.0.0.1:8383", {
.api_token = "my-token"
});
// Remove the bucket with the name "bucket-to-remove"
auto [bucket, get_err] = client->GetBucket("bucket-to-remove");
assert(get_err == Error::kOk);
auto remove_err = bucket->Remove();
assert(remove_err == Error::kOk);
// Check that the bucket no longer exists or is in the process of being removed
auto [_, get_err2] = client->GetBucket("bucket-to-remove");
assert(get_err2.code == 404 || get_err2.code == 409);
}
#!/bin/bash
set -e -x
API_PATH="http://127.0.0.1:8383/api/v1"
AUTH_HEADER="Authorization: Bearer my-token"
curl -X DELETE \
-H "${AUTH_HEADER}" \
-a "${API_PATH}"/b/bucket-to-remove
Removing a bucket will also remove all the data stored in it. This action is irreversible.
Pay attention that removing a bucket doesn't remove it immediately. The bucket is marked as DELETING, and the cleanup continues in the background. During this time, you cannot access the bucket or its entries. Once the deletion is complete, the bucket and all its data are permanently removed from the store.