How to Use Reductstore as a Data Sink for Kafka

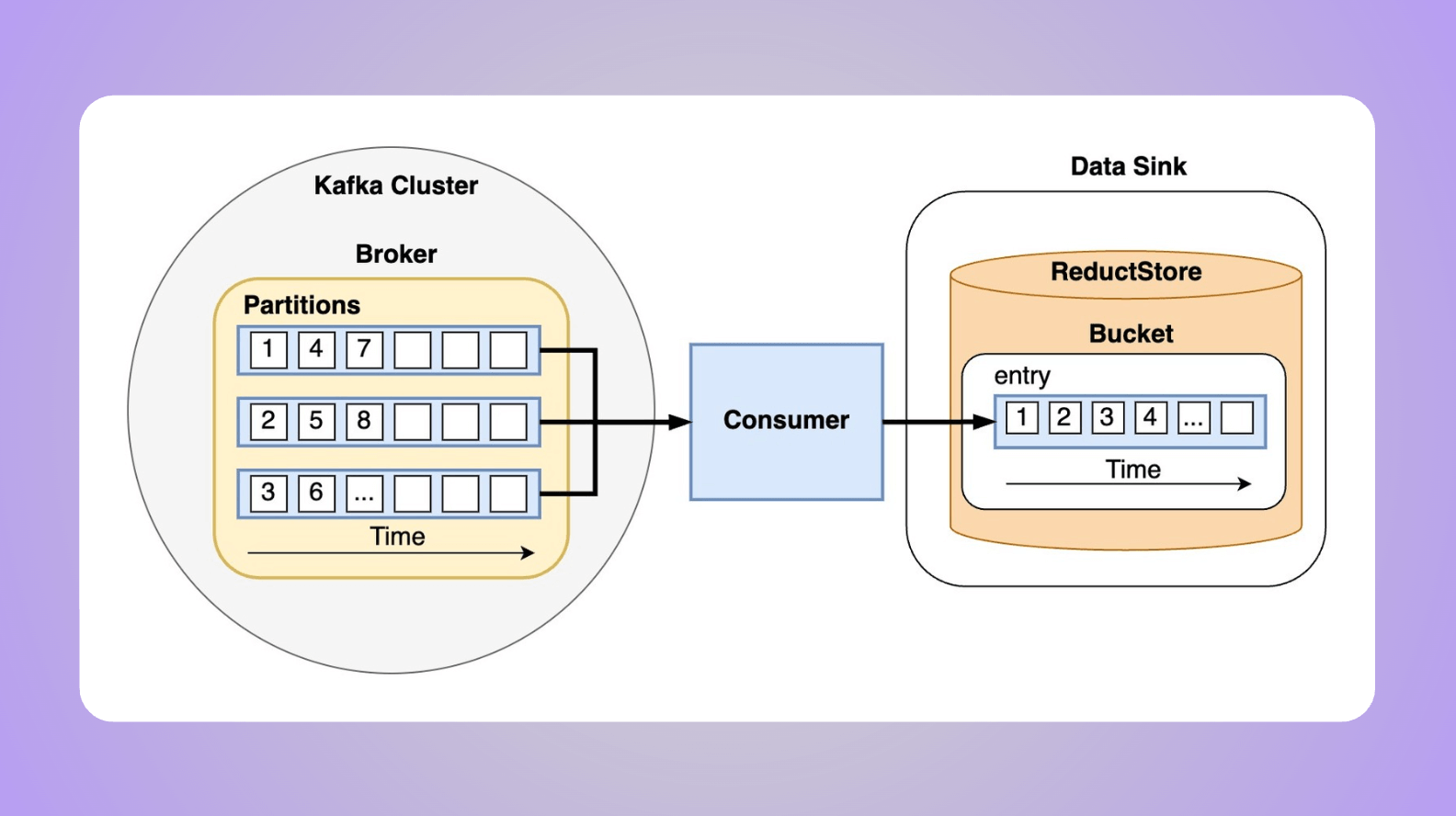
In this guide, we will explore the process of storing Kafka messages that contain unstructured data into a time series database.
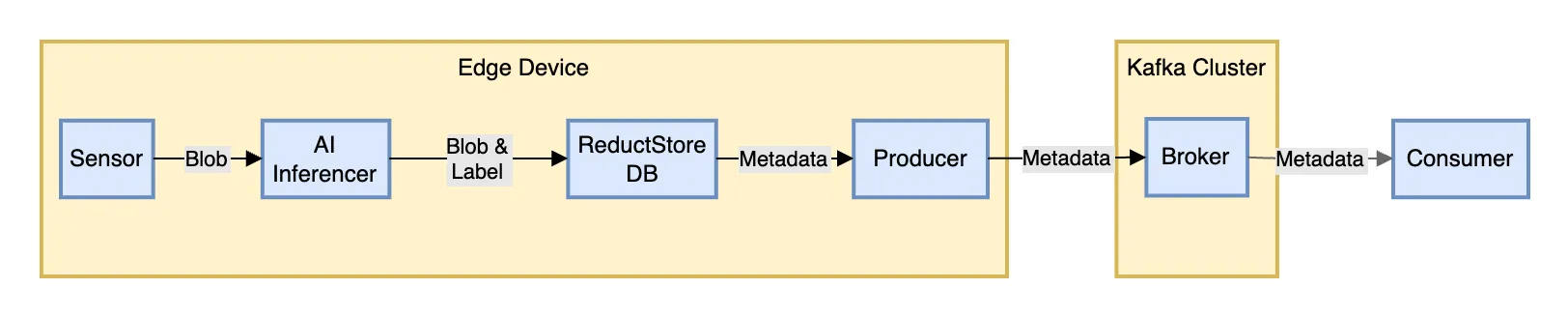
Apache Kafka is a distributed streaming platform capable of handling high throughput of data, while ReductStore is a databases for unstructured data optimized for storing and querying along time.
ReductStore allows to easily setup a data sink to store blob data for applications that need precise time-based querying or a robust system optimized for edge computing that can handle quotas and retention policies.
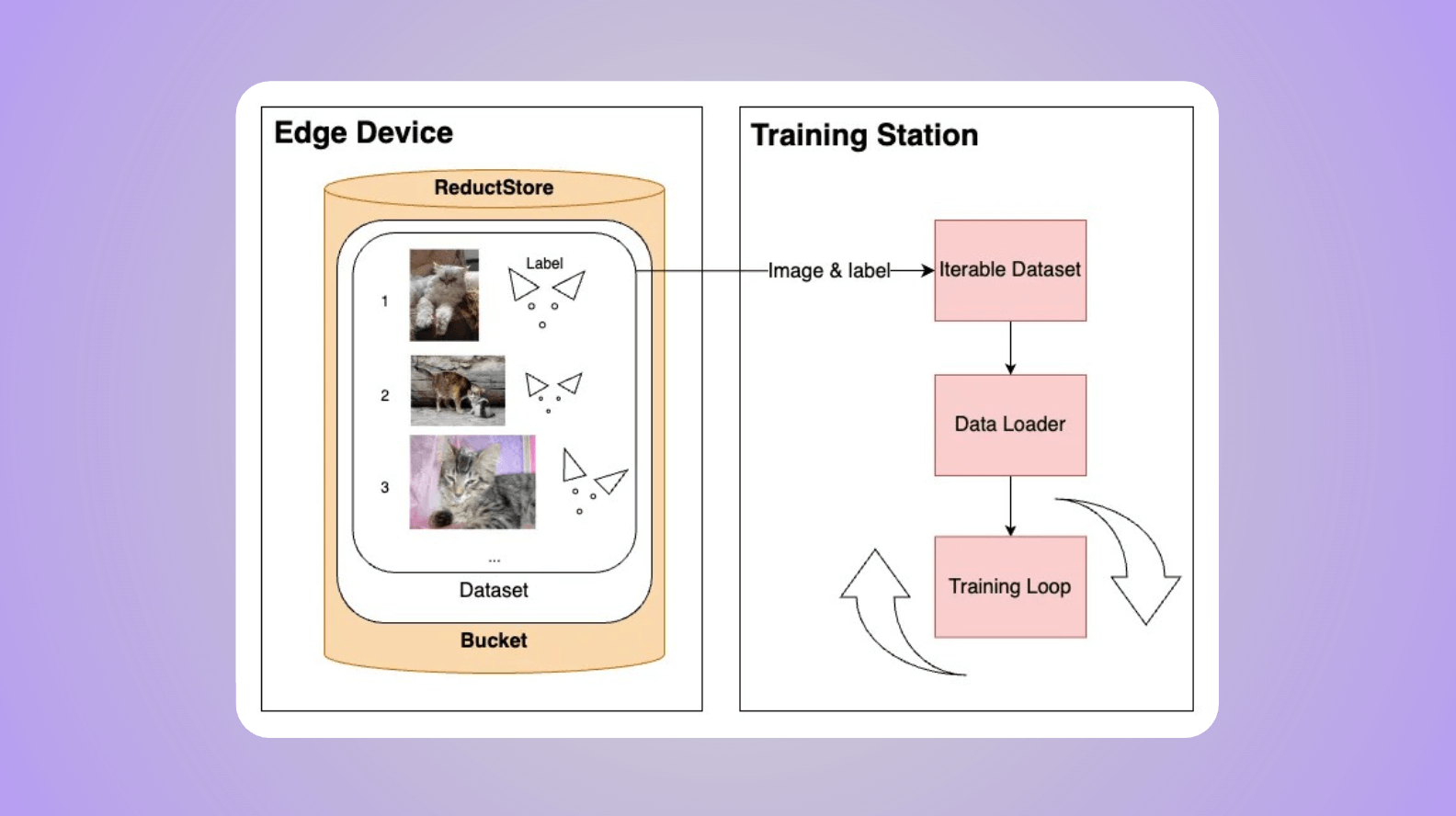
This guide builds upon an existing tutorial which provides detailed steps for integrating a simple architecture with these systems. To get started, revisit "Easy Guide to Integrating Kafka: Practical Solutions for Managing Blob Data" if you need help setting up the initial infrastructure.
You can also find the code for this tutorial in the kafka_to_reduct demo on GitHub.