Release v1.11.0: Changing labels and storage engine optimization

We are pleased to announce the release of the latest minor version of ReductStore, 1.11.0. ReductStore is a time series database designed for storing and managing large amounts of blob data.
To download the latest released version, please visit our Download Page.
What's New in ReductStore v1.11.0
In this release, we have introduced a new API for changing the labels of existing records and optimized the storage engine to improve database startup and write performance.
Change Labels API
ReductStore v1.11.0 introduces a new API for changing labels of existing records. This API allows you to update labels of one or more records in an entry without modifying or copying the record data. This is useful if you can't label data on the fly during write operations and need to update the labels later.
We have already updated all our official SDK and you can start using this feature right away. Here is an example of how to use the new API in the Python SDK:
from reduct import Client, Bucket, Batch
async def main():
# Create a client instance, then get or create a bucket
async with Client("http://127.0.0.1:8383", api_token="my-token") as client:
bucket: Bucket = await client.create_bucket("my-bucket", exist_ok=True)
# Update labels of a record: remove "key2" and update "key1"
timestamp = 1000
await bucket.update("py-example", timestamp, labels={"key1": "new-value", "key2": ""})
async with bucket.read("py-example", timestamp) as record:
assert record.labels["key1"] == "new-value"
assert "key2" not in record.labels
# Update labels in a batch
batch = Batch()
batch.add(timestamp, labels={"key1": "new-value", "key2": ""})
batch.add(timestamp + 1, labels={"key3": "value3"})
errors = await bucket.update_batch("py-example", batch)
assert not errors
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Storage Engine Optimization
Previously, ReductStore used a straightforward approach to writing data to disk. When a new record arrives from the HTTP front-end, the storage engine writes its metadata, such as timestamp, size, labels, etc., into a block descriptor and streams the record content into a data block. When the database is started, it reads all the data descriptors to build a block index and count the disk usage, which is important for the FIFO quota. It worked quite quickly on NVMe disks with terabytes of data, but users on slower disks found that starting the database could take minutes.
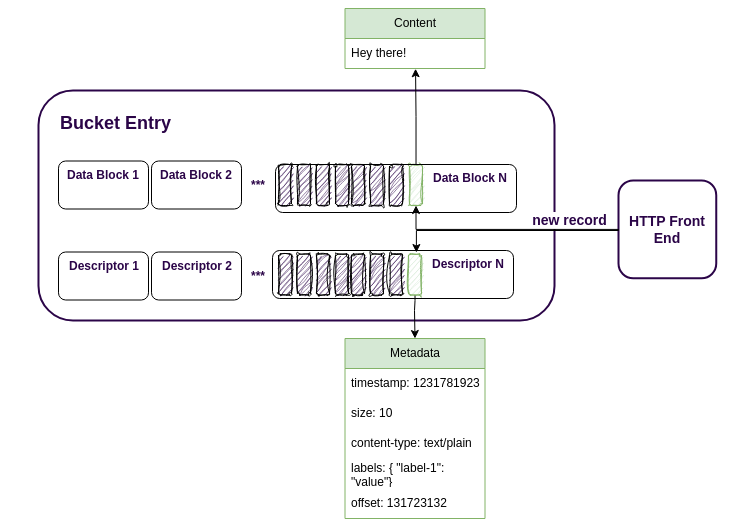
To speed up the start of the storage engine, we now store the block index for each entry on the disk. This means that the engine doesn't have to read and parse thousands of block descriptors when it starts, instead it loads one block index per entry.
However, this approach brings us to another problem... what if the database was killed or crashed while updating the index file or descriptor? We could have unsynchronised indexes or orphaned blocks. To avoid this, we introduced write ahead logs (WAL). This is a classic approach, before updating a block descriptor or block index, the storage engine writes the change to the WAL. After the changes are successfully committed, the WAL is removed. During startup, the database uses the existing WALs to restore integrity after a failure.
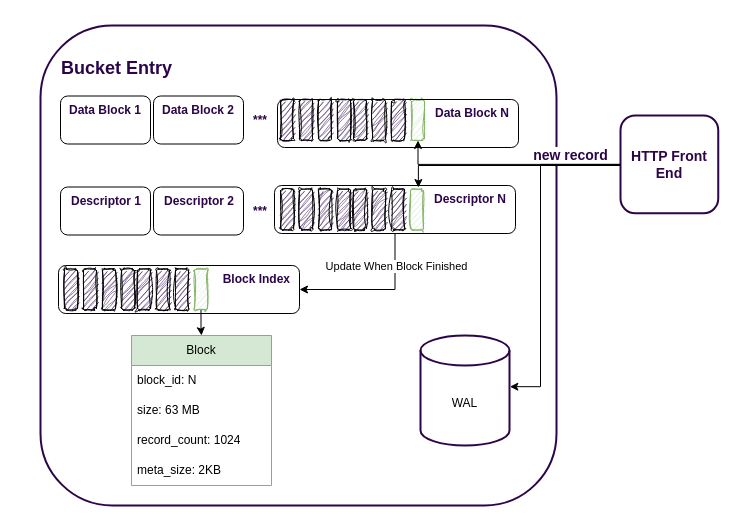
Another advantage of using WALs is that we don't have to update a block descriptor for each new record. We just need to append the WAL and update the descriptor and block index only when the block is complete. This improves write performance by up to 25% on modern hardware.
I hope you find this release useful. If you have any questions or feedback, don’t hesitate to use the ReductStore Community forum. Thanks for using ReductStore!